What the Artificial Analysis Intelligence Index Says About Opus 4.8
Claude Opus 4.8 is Anthropic’s latest large language model, designed to improve reasoning, coding, and autonomous task execution, and its benchmark results show how modern AI systems are judged on a mix of independent indices, task-specific tests, and real-world workflows rather than raw size alone. Artificial Analysis reports that Opus 4.8 scores 61.4 on the Artificial Analysis Intelligence Index, ahead of GPT-5.5 (xhigh) at 60.2, giving Anthropic a narrow but notable lead in an independent cross-model comparison. This index aggregates performance across diverse tasks, turning dozens of individual measures into a single headline number for AI model comparison. While the difference is small, it confirms that Opus 4.8’s gains over Opus 4.7 are not limited to Anthropic’s internal tests. For teams deciding between GPT-5.5 vs Claude, the index serves as a quick signal that Opus 4.8 belongs at the top of any evaluation shortlist.

How Claude Opus 4.8 Benchmarks Improve on Opus 4.7
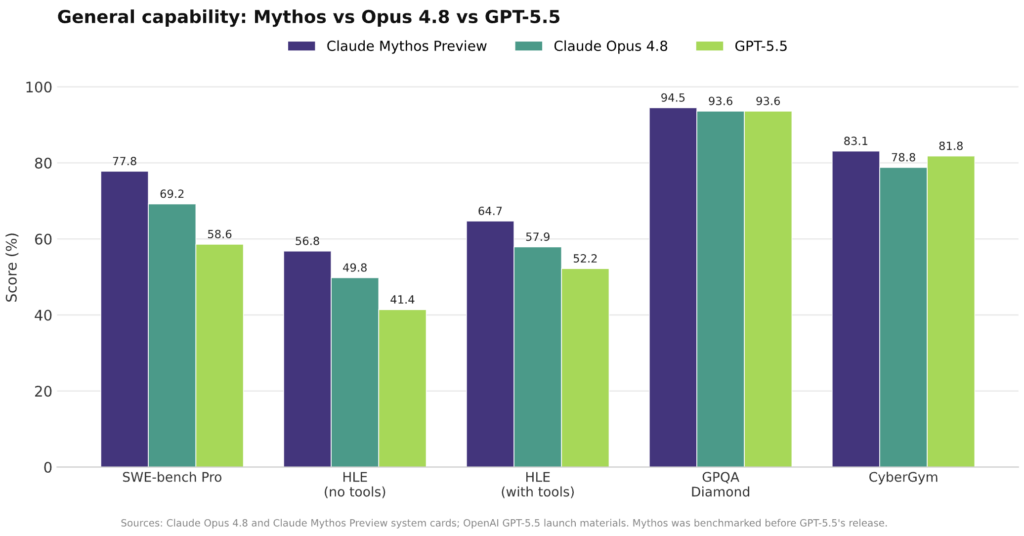
Anthropic’s own figures show Opus 4.8 outperforming Opus 4.7 on most headline benchmarks, pointing to a steady step up rather than a single narrow tweak. On agentic coding with SWE-Bench Pro, Opus 4.8 reaches 69.2% versus 64.3% for Opus 4.7, closing more real GitHub issues in large codebases. Multidisciplinary reasoning on Humanity’s Last Exam rises to 49.8% without tools and 57.9% with tools, again ahead of its predecessor. In practical computer use, Opus 4.8 scores 83.4% on OSWorld-Verified, slightly above Opus 4.7’s 82.8%. Knowledge work, measured by GDPval-AA, climbs from 1753 to 1890. Even on Terminal-Bench 2.1, where it does not lead the field, Opus 4.8 still improves over Opus 4.7, moving from 66.1% to 74.6%. All of these advances arrive at the same listed price as Opus 4.7, USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens.
GPT-5.5 vs Claude: Where Opus 4.8 Pulls Ahead
The independent index score sets the tone, but the task-level Claude Opus 4.8 benchmarks sharpen the GPT-5.5 vs Claude picture. In SWE-Bench Pro agentic coding, Opus 4.8 reaches 69.2% compared with GPT-5.5’s 58.6%, a double-digit gap on complex software maintenance. On Humanity’s Last Exam, Opus 4.8 scores 49.8% without tools and 57.9% with tools, ahead of GPT-5.5’s reported values in both settings. For agentic computer use, Opus 4.8’s 83.4% on OSWorld-Verified beats GPT-5.5 at 78.7%, and on knowledge work (GDPval-AA) it lands at 1890 versus 1769. The main exception is agentic terminal coding on Terminal-Bench 2.1, where GPT-5.5 leads with 78.2% while Opus 4.8 comes in at 74.6%. This mix suggests that Opus 4.8 is strongest when tasks demand longer sequences of reasoning and tool use, rather than isolated command-line steps.
Agentic Workflows, Fast Mode, and What Metrics Matter Most
Opus 4.8 is built around extended, semi-autonomous work sessions, so some benchmarks matter more than others when judging large language model performance for real deployments. Agentic coding (SWE-Bench Pro), OSWorld-Verified, and GDPval-AA map most directly to the promise of handing off a feature build, paperwork draft, or research pass to an AI and expecting end-to-end progress. Anthropic pairs Opus 4.8 with a Fast Mode that runs the same model at about 2.5x speed, priced at one-third of the previous cost; in Claude Code, developers can toggle it with the /fast command. For complex engineering tasks, Anthropic is also previewing dynamic workflows that let Opus plan, spin up many subagents, and perform verification before returning results. Together with the independent Artificial Analysis Intelligence Index lead, these results signal that progress in reasoning and task execution is arriving as a sequence of focused, measurable gains rather than a single dramatic jump.





