What Claude Opus 4.8 Is and Why Its New Benchmarks Matter
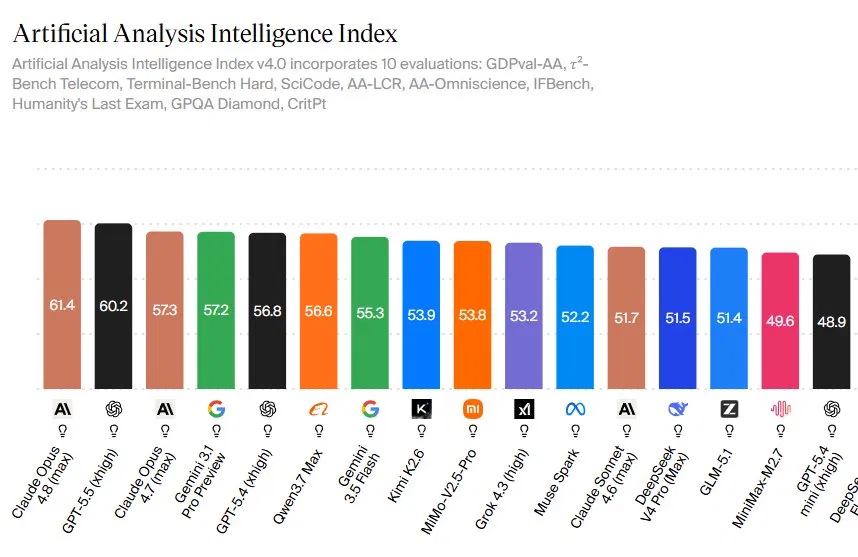
Claude Opus 4.8 is Anthropic’s latest flagship large language model, designed to excel at long, autonomous knowledge work and complex software tasks, and its leading scores on several independent AI model benchmarks indicate that it now ranks among the most capable general-purpose AI systems available for enterprise and developer use. On the Artificial Analysis Intelligence Index v4.0, Opus 4.8 scores 61.4, ahead of GPT-5.5’s 60.2 and Opus 4.7’s 57.3, a spread built across ten diverse evaluations rather than a single niche test. The index spans agentic coding, multidisciplinary reasoning, terminal work, scientific coding, and high-end question answering, giving a broad view of large language model performance. According to Artificial Analysis, this composite ranking reflects “one of the most comprehensive AI capability snapshots available,” and the 1.2-point lead suggests a model that wins consistently rather than occasionally.
GDPval-AA and the Real-World Task Edge Over GPT-5.5
The clearest sign of Claude Opus 4.8’s progress over GPT-5.5 appears on the GDPval-AA benchmark, which measures how well models perform agentic real-world tasks using web and shell access across 44 occupations and 9 industries. Opus 4.8 debuts with an Elo score of 1890, placing it 121 points ahead of GPT-5.5 and 137 points above Opus 4.7. GDPval-AA’s designers describe it as targeting “economically valuable tasks that enterprise deployments actually face,” so gains here speak directly to business impact, not laboratory puzzles. In implied head-to-head terms, Opus 4.8’s lead translates to about a 67% win rate against GPT-5.5 at comparable effort settings. This performance shift is notable because GPT-5.5 had only recently taken the top spot on the same benchmark, and the quick reversal highlights how fast AI capability rankings can change as each new model release lands.
Beyond One Number: Strengths Across Coding, Tools, and Knowledge Work
Looking beneath the composite scores, Claude Opus 4.8 shows gains across several high-value domains that matter for developers and knowledge workers. On SWE-Bench Pro, a demanding agentic coding benchmark, Opus 4.8 reaches 69.2%, up from Opus 4.7’s 64.3% and ahead of GPT-5.5’s 58.6. On Humanity’s Last Exam, which tests multidisciplinary reasoning, it scores 49.8% without tools and 57.9% with tools, leading GPT-5.5 and Gemini 3.1 Pro. For agentic computer use on OSWorld-Verified, Opus 4.8 hits 83.4%, again slightly ahead of Opus 4.7 and clearly ahead of GPT-5.5 at 78.7. Its knowledge work performance mirrors the GDPval-AA leaderboard, and it also leads on Finance Agent v2 for agentic financial analysis. Together, these results point to a model that handles multi-step workflows, tool use, and domain-specific tasks more reliably than many of its peers.
Trade-Offs: Turn Efficiency, Speed Options, and Enterprise Adoption
The benchmark wins come with trade-offs that enterprises will notice when deploying Claude Opus 4.8 at scale. Compared with Opus 4.7, the new model is more efficient, reaching higher GDPval-AA scores with 15% fewer turns per task and 35% fewer output tokens. However, it still uses about 30% more turns than GPT-5.5 to complete similar real-world tasks, placing it slightly outside the “most attractive quadrant” where high Elo scores meet low interaction counts. For high-volume agentic workflows, this extra back-and-forth can translate into higher operational cost, even if task success rates are higher. Anthropic’s answer is a new Fast Mode, which runs Opus 4.8 at roughly 2.5x the speed at one-third the standard cost, accessible in Claude Code via a /fast command. That mix of stronger performance, stable pricing, and speed tiers will likely shape how engineering teams and enterprises weigh Opus 4.8 against GPT-5.5 in their tool stacks.





