
What Claude Opus 4.8 Is and Why Its Benchmarks Matter
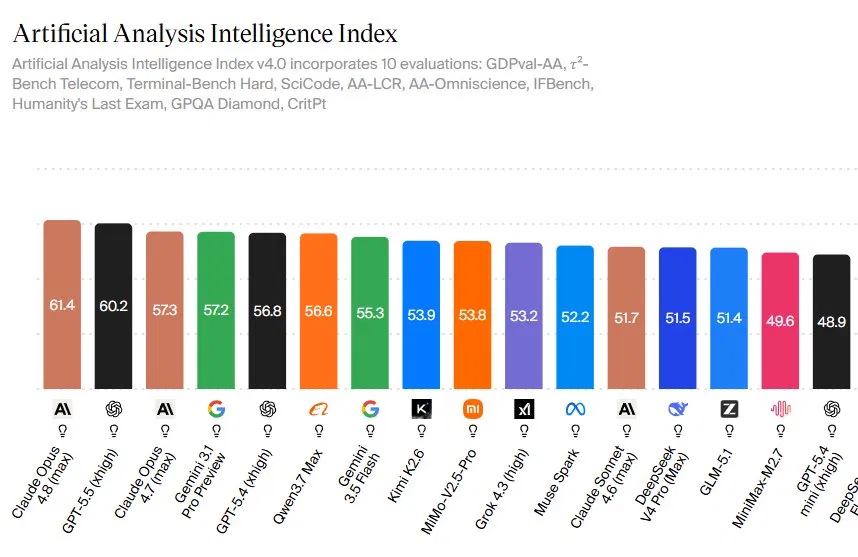
Claude Opus 4.8 is Anthropic’s newest flagship large language model, designed to improve practical reasoning, agentic workflows, and coding performance while remaining aligned with user interests, and it now sits at the top of several independent AI benchmark rankings that compare leading systems such as GPT-5.5 and Gemini 3.1 Pro. Released on 28 May as an upgrade to Opus 4.7, the model was quickly spotted in Claude Code selectors before Anthropic formally announced it. The standout data point is its score of 61.4 on the Artificial Analysis Intelligence Index v4.0, ahead of GPT-5.5’s 60.2 and Opus 4.7’s 57.3. That composite index blends ten evaluations and is widely treated as a snapshot of overall large language model performance. Based on these public scores, Anthropic now positions Claude Opus 4.8 as the most capable broadly available model.
Across-the-Board Gains: From Composite Index to Agentic Coding
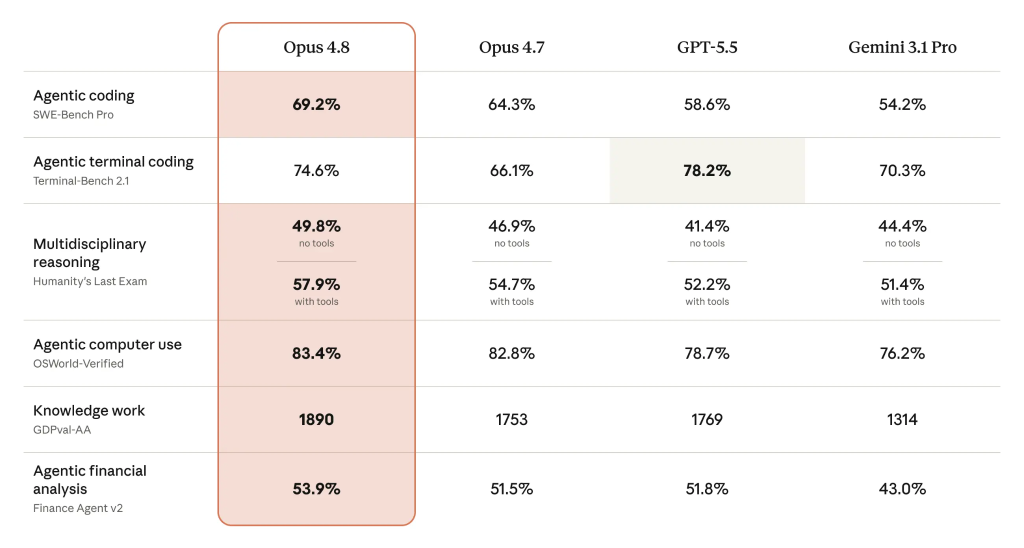
Anthropic’s evaluation data and third-party indices show Claude Opus 4.8 building its lead through consistent gains rather than one-off peaks. On the Artificial Analysis Intelligence Index v4.0, it posts 61.4, ahead of GPT-5.5’s 60.2, Gemini 3.1 Pro Preview’s 57.2, and GPT-5.4’s 56.8. The same pattern shows up in task-specific tests. Opus 4.8 reaches 69.2% on SWE-Bench Pro for agentic coding, versus 64.3% for Opus 4.7, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. It also leads on Humanity’s Last Exam for multidisciplinary reasoning, scoring 49.8% without tools and 57.9% with tools, and on OSWorld-Verified for agentic computer use at 83.4%. The only major area where it trails is agentic terminal coding: GPT-5.5 tops Terminal-Bench 2.1 at 78.2%, ahead of Opus 4.8’s 74.6%.
GDPval-AA and Real-World Work: Where Opus 4.8 Pulls Away
The clearest sign that Claude Opus 4.8 is more than a paper champion comes from the GDPval-AA benchmark, which measures agentic performance on real-world work tasks using web and shell access across 44 occupations and 9 industries. According to Artificial Analysis, Opus 4.8 reaches an Elo score of 1890 at its max effort setting, 121 points above GPT-5.5’s second-place result and 137 points higher than Opus 4.7. This translates to an implied win rate of about 67% in head-to-head comparisons against GPT-5.5 xhigh, a meaningful edge rather than a statistical tie. The model also improves efficiency versus its predecessor, using 15% fewer turns and 35% fewer output tokens per task than Opus 4.7, although it still requires roughly 30% more turns than GPT-5.5 for the same work, which may matter for cost-sensitive deployments.
Effort Controls, Dynamic Workflows, and Fast Mode
Beyond headline scores, Claude Opus 4.8 adds features aimed at long-running and large-scale workloads. A new effort control lets users dial how hard the model thinks: high effort makes it "think more frequently and more deeply" for better answers, while low effort trades depth for speed and slower rate-limit consumption. In research preview, dynamic workflows extend this further by allowing Claude Code to plan multi-step work and spin up hundreds of parallel subagents in a single session, then verify their outputs before returning results. Anthropic highlights codebase-scale migrations as a target use case, spanning hundreds of thousands of lines of code. Fast Mode for Opus 4.8 runs the same model at about 2.5x speed and is described as three times cheaper than previous fast offerings, while keeping the underlying capabilities intact.
Honesty, Alignment, and the New Peaking Order of AI Models
Anthropic emphasizes that Claude Opus 4.8 is not only stronger on benchmarks but also better behaved. The company reports that the model reaches new highs on its internal measures of prosocial traits, with improved support for user autonomy and best interests, and substantially lower rates of deception and cooperation with misuse. It also claims Opus 4.8 is around four times less likely than Opus 4.7 to let flaws in its own code slip by without comment, and early testers describe it as more reliable and sharper in judgment on agentic tasks. Taken together — top AI benchmark rankings, clear GDPval-AA gains, and alignment-focused changes — these results explain why Anthropic now presents Claude Opus 4.8 as the most capable model available, while GPT-5.5 and Gemini 3.1 Pro compete within a tightening second tier.





