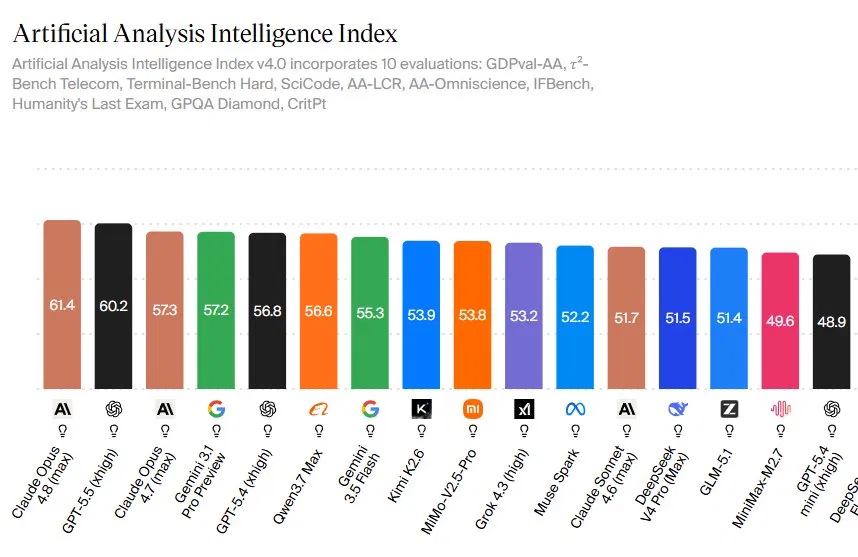
What Claude Opus 4.8’s Benchmark Lead Really Means
Claude Opus 4.8 is Anthropic’s flagship large language model that currently tops several independent AI benchmarks, signaling higher real-world performance quality for coding, reasoning, and complex work tasks compared with many competing systems. On the Artificial Analysis Intelligence Index v4.0, Claude Opus 4.8 scores 61.4, ahead of GPT 5.5 at 60.2 and Opus 4.7 at 57.3, making it the highest-ranked model on one of the most comprehensive capability snapshots available. The 1.2-point advantage over GPT 5.5 looks narrow but comes from gains spread across 10 varied evaluations rather than a single strong category. For teams evaluating large language model performance, that breadth matters: it signals a model that can support everything from research and analysis to interactive tools and agents, instead of being tuned for a single headline task.
GDPval-AA: From Benchmark Scores to Real-World Task Delivery
The clearest signal for enterprises is Claude Opus 4.8’s performance on GDPval-AA, a benchmark built to mirror economically valuable work. It measures how well models act as agents on real-world tasks using web and shell access across 44 occupations and nine industries. Opus 4.8 achieves an Elo score of 1890, which is 121 points higher than GPT 5.5 and 137 points above Opus 4.7 at max effort. According to Artificial Analysis, this translates into an implied win rate of about 67% for Opus 4.8 when compared directly with GPT 5.5 xhigh. For businesses, that edge maps to more tasks completed accurately with less human correction: think drafting multi-step reports, processing messy data, or coordinating tool calls in long-running workflows where small improvements compound into major productivity gains.
Code, Reasoning, and Tool Use: Practical Gains Over Previous Versions
Beyond headline scores, Claude Opus 4.8 displays concrete improvements where developers feel them most: code quality, reasoning depth, and reliable tool use. On SWE-Bench Pro, which tracks agentic coding on real repositories, Opus 4.8 scores 69.2%, up from 64.3% for Opus 4.7 and well ahead of GPT 5.5 at 58.6. It also leads on multidisciplinary reasoning with a 57.9% score on Humanity’s Last Exam with tools, and achieves 83.4% on OSWorld-Verified for agentic computer use. These jumps suggest fewer hallucinated APIs, better long-range planning, and more consistent follow-through in codebases and desktop environments. Internally, Opus 4.8 also reaches higher GDPval-AA scores using 15% fewer turns and 35% fewer output tokens than Opus 4.7, turning benchmark progress into more efficient, higher-quality assistance for development and knowledge work teams.
GPT 5.5 vs Claude: Speed, Efficiency, and Enterprise Trade-Offs
The GPT 5.5 vs Claude Opus 4.8 comparison is not one-sided. While Opus 4.8 leads most capability metrics, it still uses about 30% more turns per task than GPT 5.5 on GDPval-AA. In practice, that means Opus often takes more interaction steps to reach its stronger outcome. For cost-sensitive, high-volume agentic workflows, this turn gap is a serious factor in AI model comparison, especially where latency and throughput dominate. That said, Opus 4.8 keeps the same price point as Opus 4.7 and adds a Fast Mode that runs the identical model at roughly 2.5x speed for one-third the standard cost. Enterprises weighing large language model performance against budget will be choosing between GPT 5.5’s efficiency and Claude’s higher task completion quality, with pricing options that narrow the gap.
Why Performance Leadership Matters for Developers and Enterprises
Performance leadership on benchmarks is shifting quickly, but it already shapes real buying decisions. Anthropic positions Claude Opus 4.8 for long, largely autonomous work: in Claude Code, 16 parallel Claude instances have been shown autonomously building a C compiler from scratch, and the company says the model behaves like an experienced engineer who does not need constant check-ins. For engineering teams, this means handing off feature builds, migrations touching hundreds of files, or bug sweeps and focusing on higher-level design. For enterprises, leading scores on GDPval-AA, finance-focused benchmarks, and agentic computer use suggest a model that can support AI agents spanning operations, analysis, and support. As mid-tier models cluster in similar ranges, the gap at the top between Claude Opus 4.8 and GPT 5.5 becomes a key signal of where complex, high-value workloads are likely to run best.





