What Claude Opus 4.8 Is and Why It Matters
Claude Opus 4.8 is Anthropic’s latest flagship large language model, designed to combine high scores on AI model benchmarks with better honesty, lower deceptive behavior, and cheaper usage options for real-world applications across coding, research, and enterprise automation. Independent firm Artificial Analysis reports that Opus 4.8 scores 61.4 on its Intelligence Index, placing it narrowly ahead of GPT-5.5’s 60.2 in overall capability. While the upgrade from Opus 4.7 looks incremental at first glance, Anthropic’s system card shows improvements in reasoning, tool use, and complex software tasks. At the same time, the model is evaluated as “much weaker than Mythos on cyber,” which signals that Anthropic has deliberately separated a general-purpose flagship from its high-risk cybersecurity specialist tier, Claude Mythos.

Independent Benchmarks: Opus 4.8 vs GPT-5.5 and Mythos
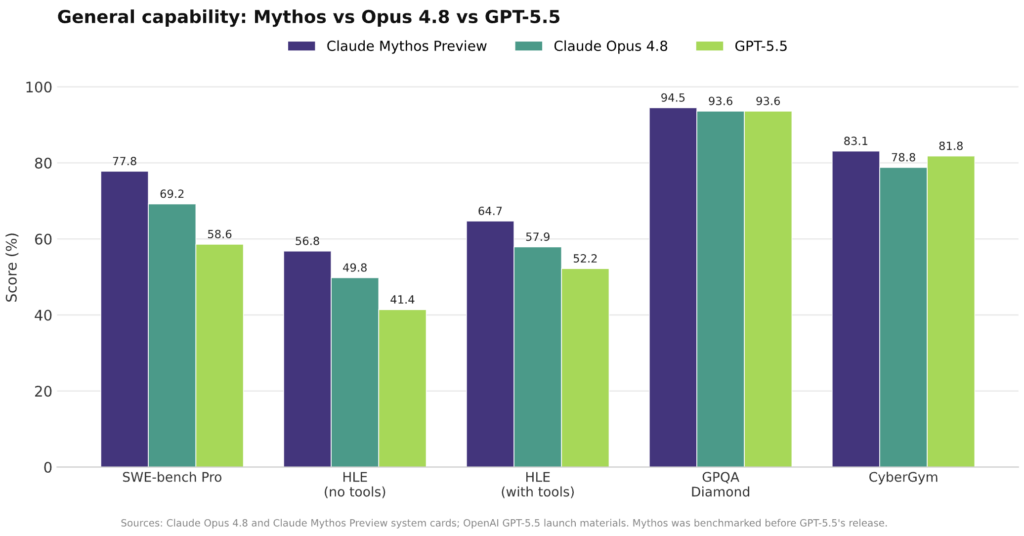
Artificial Analysis ranks Claude Opus 4.8 first on its Intelligence Index at 61.4, with GPT-5.5 close behind at 60.2, making this a tight Claude vs OpenAI race at the frontier. On task-level AI model benchmarks, Anthropic’s system cards show Mythos ahead of Opus 4.8 on demanding software problems like SWE-bench Pro, where Mythos scores 77.8 against Opus 4.8’s 69.2 and GPT-5.5’s 58.6. For high-level evaluations (HLE), Opus 4.8 sits between Mythos and GPT-5.5 both with and without tools, while all three models cluster near 94 on GPQA Diamond’s graduate-level science questions. These results suggest Opus 4.8 is a strong generalist, Mythos is the most capable on the hardest coding and cyber tasks, and GPT-5.5 remains highly competitive on reasoning and browsing-heavy workloads.
Honesty, Deception, and Safety: How Opus 4.8 Changes the Tradeoffs
Anthropic reports that Claude Opus 4.8 “reaches new highs” on its prosocial trait measures, with a lower chance of cooperating with misuse and a higher tendency to admit uncertainty. Their internal evaluations indicate that Opus 4.8 is four times less likely to hide flaws in the code it writes compared with earlier Claude models, which directly affects trust for critical software and data workflows. The same Opus 4.8 system card notes a large gap between Opus 4.8 and Mythos in cyber capability: with safeguards off, Mythos can produce full working exploits on far more Firefox and OSS-Fuzz targets than Opus 4.8. In practice, this means Opus 4.8 aims to be safer and less deceptive as a default assistant, while Mythos is positioned as a specialized tier where cyber power is concentrated under stricter access and policy controls.
AI Pricing Comparison and Effort Controls for Real-World Use
On cost, Opus 4.8 keeps the same base price as Opus 4.7 at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, but introduces a new fast mode that Anthropic says is three times cheaper than the previous fast tier. In contrast, the Mythos Preview launched at USD 25 (approx. RM115) per million input tokens and USD 125 (approx. RM575) per million output tokens, five times the Opus rate, highlighting a clear AI pricing comparison between the general-purpose and cyber-advanced tiers. Anthropic also added Effort controls so users can choose Low, Medium, High, or Max effort, trading latency and token consumption against depth. For developers and enterprises, this mix of cheaper fast mode, predictable base pricing, and explicit effort settings makes Opus 4.8 easier to integrate into cost-sensitive workflows than Mythos or many GPT-5.5 setups.
Dynamic Workflows and When to Choose Each Model
Beyond raw benchmarks, Opus 4.8 gains new Dynamic workflows in research preview, where Claude can break a large problem into hundreds of concurrent subagents, coordinate them in Claude Code, and verify outputs before presenting results. This feature is well suited to long, multi-step projects such as refactoring sizeable codebases or running complex research pipelines, and it plays to Opus 4.8’s balanced strengths in reasoning, browsing, and tool use. In day-to-day GPT-5.5 comparison scenarios, Opus 4.8’s slight Intelligence Index lead, improved honesty, and cheaper fast mode make it an attractive default for many teams. Mythos remains the choice when the work demands maximum cyber and advanced software performance and the higher price and risk profile are acceptable. Together, these three models now define the upper tier of the advanced AI model landscape.





