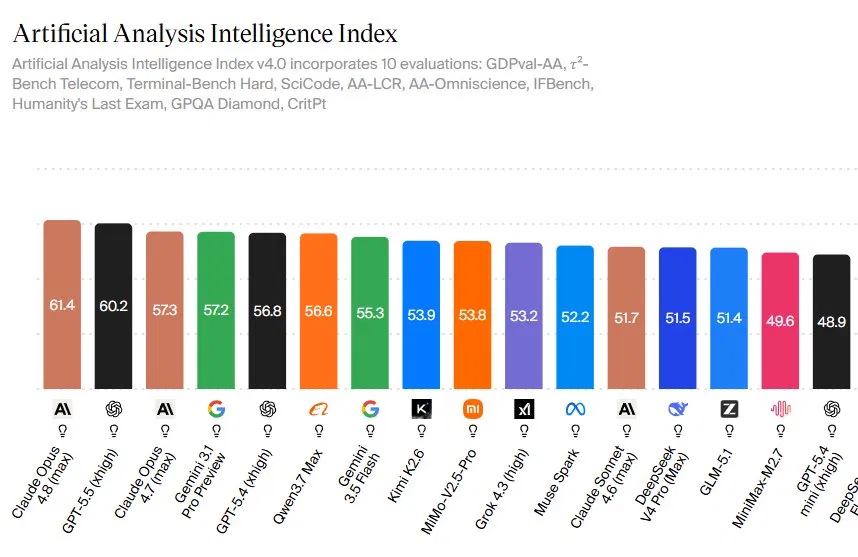
What Claude Opus 4.8’s Benchmark Win Really Means
Claude Opus 4.8 benchmark performance refers to the model’s independently measured scores across diverse AI evaluations that test reasoning, coding, tool use, and real-world knowledge work, and its recent results show a narrow lead over GPT-5.5 that signals practical gains for enterprise AI performance rather than a cosmetic upgrade. Artificial Analysis’ Intelligence Index v4.0 places Opus 4.8 at 61.4, ahead of GPT-5.5’s 60.2 and well clear of Opus 4.7’s 57.3. The index blends 10 tests spanning telecom tasks, coding, science questions, and high-stakes reasoning, so a 1.2-point edge reflects consistent strength across domains, not a single lucky spike. For businesses comparing GPT-5.5 vs Claude, this is the first clear, independent snapshot showing Anthropic’s flagship at the top of a broad capability stack, rather than matching or trailing OpenAI’s latest.
GDPval-AA: Where Real-World Enterprise Work Is Decided
For enterprises, the most important AI model comparison often comes down to how well a system performs on realistic, economically meaningful tasks. That is exactly what the GDPval-AA benchmark targets: multi-step work using web and shell access across 44 occupations and 9 industries. Opus 4.8 scores 1890 Elo here, 121 points ahead of GPT-5.5 and 137 points above Opus 4.7 at the same ‘max’ setting. According to Artificial Analysis, that margin implies “an implied win rate of approximately 67% in head-to-head comparisons against GPT-5.5 xhigh.” In practical terms, procurement teams can read this as a better chance that Claude Opus 4.8 will finish a complex workflow correctly the first time, whether it is financial analysis, research synthesis, operations documentation, or structured reporting that touches external tools and data.

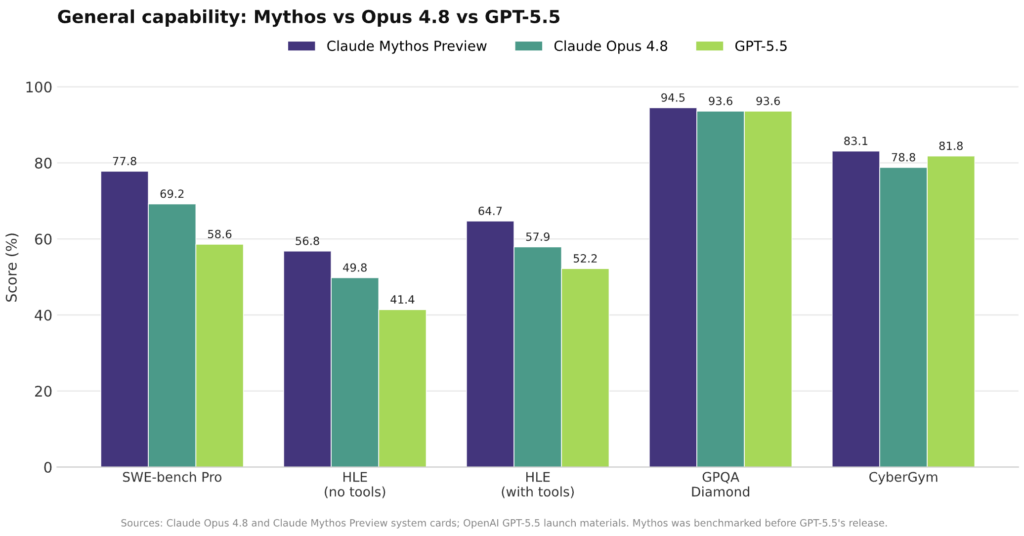
From Opus 4.7 to 4.8: A Capability Leap, Not a Tweak
The numbers show that Claude Opus 4.8 is more than a minor refresh of Opus 4.7. On agentic coding (SWE-Bench Pro), it climbs from 64.3% to 69.2%, while GPT-5.5 sits at 58.6. On Humanity’s Last Exam, Anthropic reports 49.8% without tools and 57.9% with tools, ahead of GPT-5.5 and Gemini 3.1 Pro. OSWorld-Verified, a test of agentic computer use, moves slightly from 82.8% to 83.4%, but that small bump still leaves Opus 4.8 ahead of GPT-5.5’s 78.7. GDPval-AA shows the largest jump: +137 Elo over Opus 4.7. Anthropic also says Opus 4.8 completes GDPval-AA tasks in 15% fewer turns and with 35% fewer tokens than 4.7, hinting at better planning and tighter outputs. For teams upgrading from 4.7, this is closer to a step change in autonomy and reliability than a routine version bump.
Efficiency and Cost: Where GPT-5.5 Still Bites Back
Despite its higher scores, Opus 4.8 is not a clean sweep. Artificial Analysis notes that while Opus 4.8 is more efficient than Opus 4.7, it still needs about 30% more turns per task than GPT-5.5 on GDPval-AA. On Terminal-Bench 2.1, which measures agentic terminal coding, GPT-5.5 leads at 78.2%, versus 74.6% for Opus 4.8. That matters for cost-sensitive deployments where every extra tool call or message adds latency and spend. Anthropic is countering with a Fast Mode: the same Opus 4.8 model running at roughly 2.5x the speed and priced at one-third the previous cost, while keeping the base Opus 4.8 price aligned with Opus 4.7 at USD 5 (approx. RM23) input and USD 25 (approx. RM115) output per million tokens. The trade-off is now clear: Opus 4.8 offers higher task success rates; GPT-5.5 answers more briskly per interaction.
How Enterprises Should Choose Between GPT-5.5 and Claude
Independent benchmarks now draw a sharper map for enterprise AI choices. If the priority is maximum task completion on complex, open-ended workflows, the data points toward Claude Opus 4.8: it leads the Artificial Analysis Intelligence Index at 61.4, tops GDPval-AA with a 121-point Elo margin, and outperforms GPT-5.5 on agentic coding, multidisciplinary reasoning, and agentic computer use. If the focus is short, interactive sessions with tight latency and tool budgets, GPT-5.5’s lower turn count and strong terminal performance remain attractive. The mid-tier—models like Gemini 3.1 Pro, Qwen3.7 Max, and DeepSeek V4 Pro—stays competitive but clearly behind the top two in composite scores. For most large deployments, a portfolio approach makes sense: Opus 4.8 as the primary workhorse for demanding workflows, GPT-5.5 or cheaper mid-tier models for lighter, cost-focused tasks.





