What Claude Opus 4.8’s New Benchmark Lead Really Means
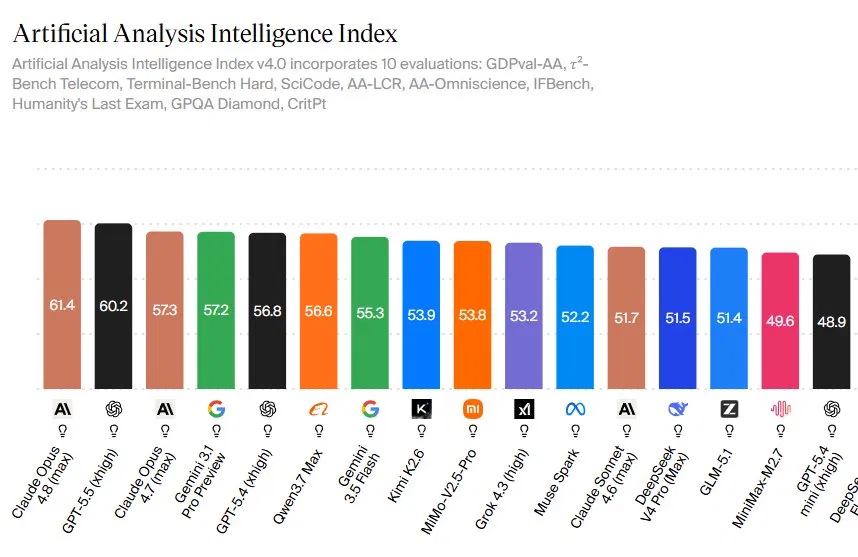
Claude Opus 4.8 is Anthropic’s latest flagship large language model, and its performance across independent benchmarks signals a shift in the AI capability hierarchy that could reshape how enterprises choose and deploy AI systems for complex, economically valuable work. Artificial Analysis reports that Opus 4.8 now tops the Artificial Analysis Intelligence Index v4.0 with a score of 61.4, ahead of GPT-5.5’s 60.2 and comfortably above Opus 4.7’s 57.3, based on an aggregate of ten diverse evaluations. That margin may look small, but it reflects consistent gains across coding, reasoning, and agentic computer use rather than a fluke win in a single category. The same pattern shows up in Anthropic’s internal data: Opus 4.8 beats both GPT-5.5 and Gemini 3.1 Pro on agentic coding, multidisciplinary reasoning, and OS-level tool use, positioning it as a general-purpose workhorse instead of a narrow specialist.
GDPval-AA: The Benchmark That Matters Most for Enterprise AI
For enterprise buyers, the GDPval-AA benchmark may matter more than the composite index. Developed by Artificial Analysis with its open-source Stirrup harness, GDPval-AA scores models on end-to-end work tasks that use web and shell access across 44 occupations and 9 industries. On this test, Claude Opus 4.8 posts an Elo score of 1890, pulling 121 points clear of GPT-5.5 in second place and improving by 137 points over Opus 4.7. That translates to an implied win rate of about 67% for Opus 4.8 in head-to-head GDPval-AA comparisons against GPT-5.5 xhigh, a gap that is far from a rounding error. In practical terms, this suggests Opus 4.8 is more likely to finish complex workflows successfully when handed real business tasks, from research and drafting to analysis and multi-step operations involving tools and browsers.

Beyond a Point-Release: Where Opus 4.8 Beats GPT-5.5 and Opus 4.7
Anthropic positions Opus 4.8 as an incremental upgrade, but the benchmark profile looks more like a broad capability step. On SWE-Bench Pro agentic coding, Opus 4.8 reaches 69.2%, beating Opus 4.7 at 64.3%, GPT-5.5 at 58.6%, and Gemini 3.1 Pro at 54.2. On Humanity’s Last Exam for multidisciplinary reasoning, it scores 49.8% without tools and 57.9% with tools, again ahead of the same rivals. OSWorld-Verified scores show 83.4% for Opus 4.8, marginally ahead of Opus 4.7’s 82.8% and comfortably ahead of GPT-5.5’s 78.7%. Even on knowledge-intensive work (GDPval-AA), Opus 4.8’s 1890 outstrips GPT-5.5’s 1769 and Opus 4.7’s 1753. GPT-5.5 still leads one area: Terminal-Bench 2.1, where it scores 78.2% against Opus 4.8’s 74.6%, hinting that some terminal-heavy automation workflows may remain more efficient on OpenAI’s model.
Trade-offs: Turn Efficiency, Pricing, and Anthropic’s Fast Mode
The Claude Opus 4.8 benchmark story is not only about accuracy; efficiency matters for large-scale deployment. On GDPval-AA, Opus 4.8 reaches its higher Elo score while using 15% fewer turns and 35% fewer output tokens than Opus 4.7, marking a clear internal efficiency gain. However, Opus 4.8 still uses about 30% more turns per task than GPT-5.5, placing it outside the most attractive “high-score, low-turn” quadrant on Artificial Analysis’s score-versus-turns scatter plot. For cost-sensitive workloads, those extra interactions can add up. Anthropic responds by keeping Opus 4.8 at the same list price as Opus 4.7, USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, and by introducing a Fast Mode that runs the same model at about 2.5x speed at one-third of the previous cost.
Implications for AI Model Comparison and Enterprise Strategy
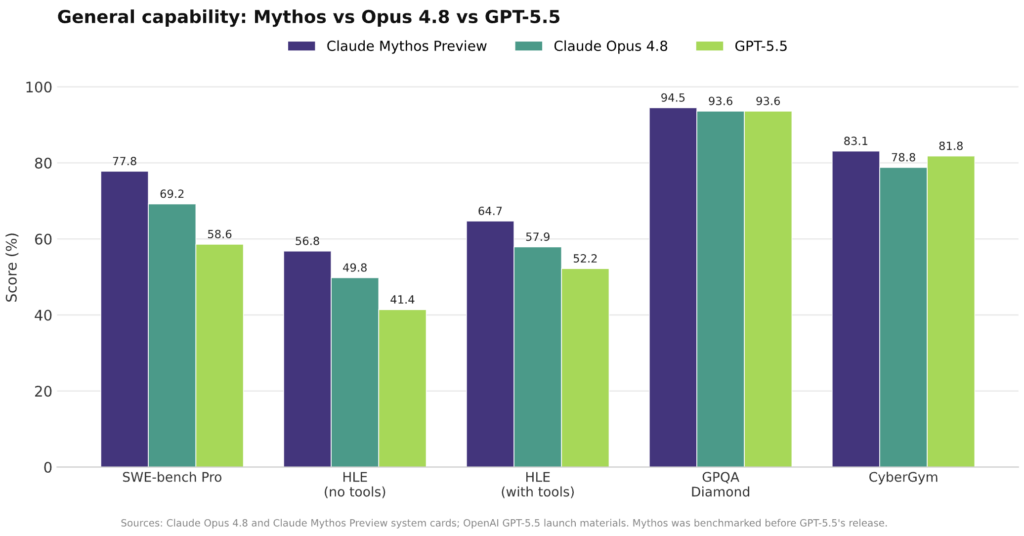
For enterprises comparing GPT-5.5 vs Claude, the latest numbers change the conversation from raw intelligence to work output. On the Artificial Analysis Intelligence Index, the top two models are now meaningfully ahead of a mid-tier cluster that includes Gemini 3.1 Pro, GPT-5.4, Qwen3.7 Max, Kimi K2.6, and MiMo-V2.5-Pro. At the very top, Opus 4.8’s win on GDPval-AA and broad lead on agentic coding and reasoning benchmarks suggest a model tuned for practical, production-grade AI capabilities. At the same time, Anthropic’s roadmap hints that Mythos, a more expensive tier with stronger performance on hard software and cyber tasks, will sit above Opus 4.8 for the most demanding use cases. For now, independent benchmarking suggests many enterprises will want to re-run their AI model comparison exercises, mapping workloads carefully: Opus 4.8 for general agentic work, GPT-5.5 where terminal efficiency dominates, and Mythos for specialized high-stakes development and security tasks.






