What Gemma 4 12B Is and Why It Matters
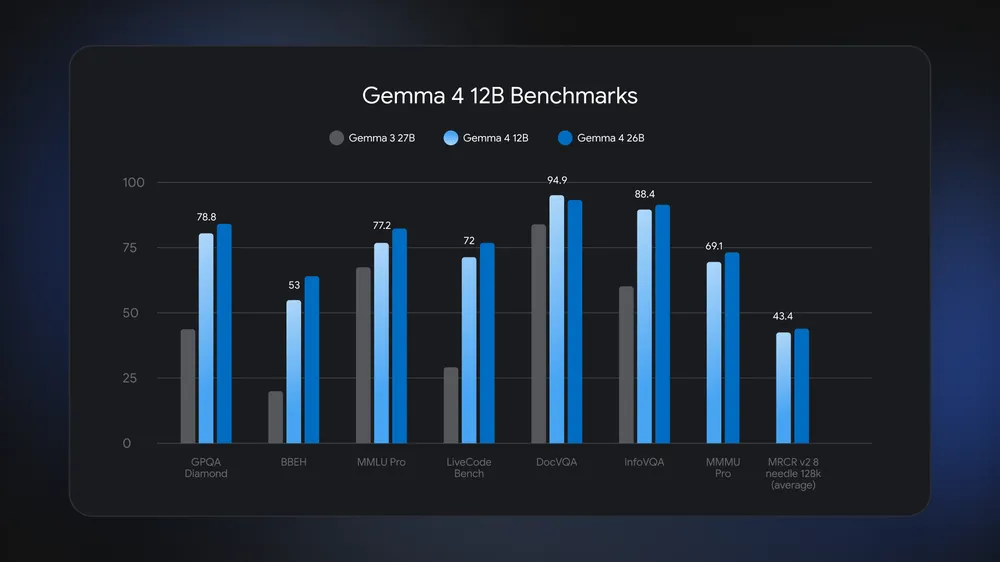
Gemma 4 12B is Google DeepMind’s 12‑billion‑parameter local multimodal AI model that runs on laptops with 16GB memory, processing text, images, audio, and code directly on-device without relying on separate encoders or cloud infrastructure. Positioned between phone‑class and workstation‑class models in the Gemma 4 family, it fills a gap for users who need more power than mobile variants without dedicated accelerators. The Gemma 4 12B model uses roughly half the memory of the 26B Mixture of Experts while staying close on benchmark scores and beating Gemma 3 27B on tests such as GPQA Diamond, MMLU Pro, and DocVQA. Because it can run locally with open weights under an Apache 2.0 license, developers can experiment with laptop AI processing and build new on-device inference workflows without subscriptions, data export, or always-on internet connections.

Encoder-Free Architecture: Multimodal AI Without the Overhead
The standout feature of Gemma 4 12B is its encoder-free architecture, which processes images and audio through the language backbone instead of separate modules. Most multimodal systems feed non-text inputs through large vision and audio encoders before handing them to the core model, adding hundreds of millions of parameters and memory overhead. Gemma 4 12B replaces 27 vision transformer layers and about 550 million parameters with a slim 35‑million‑parameter visual embedding module that slices images into 48×48 pixel patches, then projects them into the model’s hidden dimension with a single matrix multiplication. Audio is treated even more directly: raw 16 kHz waveforms are cut into 40‑millisecond frames and projected into the same vector space as text tokens. This unified design cuts latency and memory use, makes deployment simpler, and turns local multimodal AI into a realistic option for consumer laptops.
Near-26B Performance and Practical Local AI Agents
By shrinking the architecture and memory footprint, Gemma 4 12B brings capabilities once tied to larger models to standard hardware. Google reports that the Gemma 4 12B model runs on any laptop with 16GB of system RAM or VRAM while trailing the 26B Mixture of Experts only narrowly on benchmarks and beating Gemma 3 27B on key evaluation suites. This balance makes it a strong candidate for local AI agents that handle multistep reasoning, document understanding, and media analysis without cloud calls. The model supports speech recognition, speaker diarization, code generation, image understanding, and video analysis, as shown in a demo where it processed a five‑minute keynote with 313 video frames and corresponding audio. With everything running locally, developers can design privacy‑preserving assistants, offline productivity tools, and multimodal research workflows that stay within the memory budget of mainstream laptops.
LiteRT-LM and Multi-Token Prediction Speed Up On-Device Inference
LiteRT-LM, a runtime built on LiteRT (formerly TensorFlow Lite), is central to making Gemma 4 practical for on-device inference. It adds native support for Gemma 4 Multi-Token Prediction drafters, which use speculative decoding to predict multiple future tokens in parallel. According to Google, this yields up to 2.2× faster decoding for certain Gemma 4 models compared with standard token-by-token generation. LiteRT-LM keeps both the primary model and MTP drafter on the same hardware, managing shared KV caches in local memory to avoid cross‑device synchronization overhead. Its orchestration layer minimizes CPU-GPU transfers, supports advanced session management, and uses optimized XNNPACK and MLDrift kernels. Google reports that prefill and decode performance in LiteRT-LM is 1.8× to 3.7× faster than frameworks such as llama.cpp, MLX, Cactus, and ONNX, making laptop AI processing more responsive even under tight memory and compute limits.

Open Weights, Open Ecosystem: Beyond Cloud-Dependent AI
Gemma 4 12B’s open-weights release under Apache 2.0 turns it into a foundation for a broader ecosystem of local multimodal AI tools. The weights, around 18GB, are already available on platforms like Hugging Face and Kaggle, so developers can fine-tune or quantize the model for their own laptop AI processing pipelines. Combined with LiteRT-LM’s support for Android, iOS, and web platforms, the same core model can underpin desktop apps, mobile assistants, and browser-based tools without tying users to a single cloud provider. This shifts the narrative from cloud-centric AI to on-device inference where data remains local and latency is predictable. As more developers experiment with encoder-free architecture and Multi-Token Prediction, Gemma 4 12B may become a proving ground for practical, subscription-free multimodal agents that run on everyday hardware rather than specialized servers.




