What Gemma 4 12B Is and Why It Matters
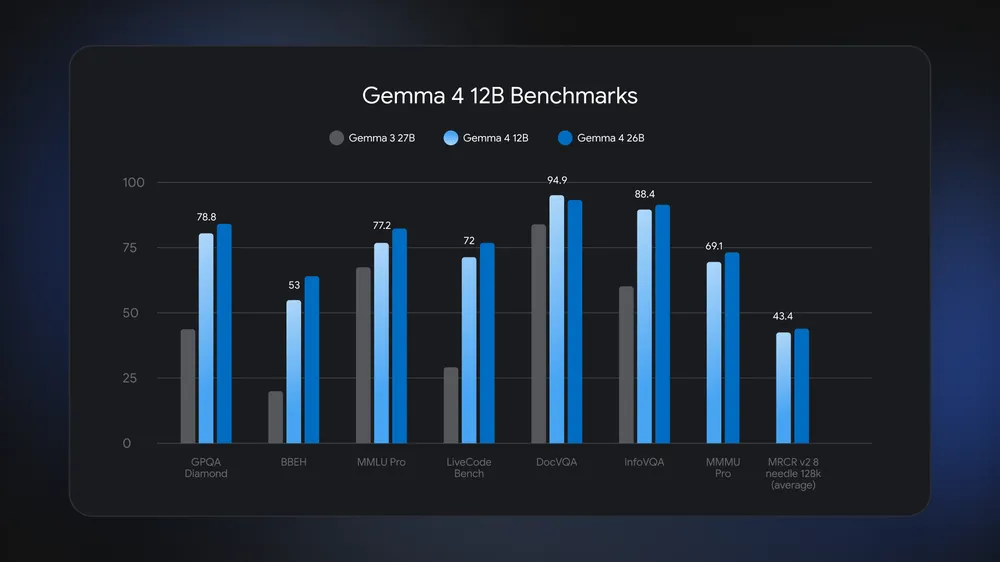
Gemma 4 12B is an open-weights multimodal AI model from Google DeepMind that runs on laptops with 16GB memory, processing text, images, audio, and code locally so developers can build advanced agents without cloud infrastructure. Positioned between phone-grade and workstation-scale models, it targets users who need strong reasoning but only have consumer hardware. Google says this 11.95‑billion‑parameter model uses about half the memory of the Gemma 4 26B Mixture of Experts while staying close to it on benchmarks and outperforming Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA. For teams exploring local multimodal AI, it offers a practical balance of capability and footprint. The result is laptop AI inference that can run multi-step workflows—such as reading screenshots, transcribing speech, and writing code—without depending on a network connection or external GPUs.

Unified, Encoder-Free Design for Multimodal Inputs
The Gemma 4 12B model stands out through a unified, encoder-free architecture that routes images and audio straight into the language-model backbone. Traditional multimodal systems bolt on separate vision and audio encoders, which add hundreds of millions of parameters, raise memory use, and increase latency on laptop-class devices. Here, images are split into 48×48 pixel patches and projected into the hidden dimension using a compact 35‑million‑parameter module, replacing the roughly 27-layer vision transformer stack in larger Gemma 4 models. Audio goes even leaner: raw 16 kHz waveforms are cut into 40‑millisecond frames and projected into the same token space as text, enabling native audio support without a dedicated encoder. This simplified design shrinks the computational footprint and makes local multimodal AI more practical, especially for agents that mix screenshots, speech, and code in the same session.
Local Multimodal AI Without Cloud Latency or Data Leaves
Running Gemma 4 12B as a local multimodal AI engine changes how applications handle data and latency. Instead of shipping screenshots, audio recordings, and documents to remote servers, everything can be processed on-device, so sensitive information never leaves the laptop. According to Google, the model is “small enough to run locally on consumer laptops with 16GB of RAM,” which opens agentic AI workflows to a large base of existing hardware. Local execution also removes network lag, so users see immediate responses even when offline or on poor connections. This makes laptop AI inference attractive for privacy-focused scenarios such as summarising confidential reports, analysing internal diagrams, or transcribing private meetings. Because there is no dependency on cloud endpoints, developers can design applications that keep working regardless of connectivity while still delivering near‑26B‑class reasoning performance.
Performance, Multi-Token Prediction, and Developer Experience
Performance-wise, Gemma 4 12B aims to close the gap with bigger models through both architecture and decoding tricks. Google reports benchmark scores approaching the Gemma 4 26B Mixture of Experts while consuming about half the memory footprint, and notes that it clearly beats Gemma 3 27B on GPQA Diamond, MMLU Pro, and DocVQA. Multi-Token Prediction (MTP) drafters ship enabled by default, using spare compute cycles to predict several future tokens at once and reduce generation latency. For developers, this means faster, more responsive laptop AI inference even for long-form outputs like code or transcripts. The model’s open-weights AI model design under Apache 2.0 licensing gives teams the freedom to fine-tune, quantize, and embed it into their own stacks without restrictive terms, making it a practical foundation for tool-calling agents, offline assistants, and domain-specific copilots.
Tooling, Use Cases, and the Future of Laptop AI Inference
Google is pairing Gemma 4 12B with a local development stack aimed at real-world deployment. The Google AI Edge Gallery app for macOS lets developers download, manage, and run models like Gemma 4 12B on-device, giving a visible workflow for integrating local multimodal AI into applications. The AI Edge Eloquent reference app goes further by showing offline voice dictation and text editing powered by the model, competing with cloud transcription services while keeping audio on the machine. These tools hint at what open-weights AI models can do locally: a financial analyst’s agent summarising confidential files, or a field engineer’s assistant reading equipment photos and pulling diagrams from a local database. As more developers customise and fine-tune Gemma 4 12B, the line between cloud-scale intelligence and laptop AI inference will narrow for many everyday workflows.