What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is a mid-sized, open-weight, multimodal on-device AI model from Google that is designed to run audio, image, text, code, and tool-call workloads entirely on consumer laptops with 16GB of shared CPU or GPU memory, shifting tasks that once needed cloud servers into local applications and agents. At its core, the model is aimed at developers who want laptop AI inference without constant network calls, especially for assistants that listen to speech, read screenshots, and write or edit code. Google positions this release as part of the Gemma 4 family, a line derived from Gemini 3 research and tuned for personal-computer-class reasoning. According to WinBuzzer, Gemma downloads have “now passed 150 million,” indicating strong interest in on-device AI models that keep data local while still supporting long-context, multimodal workflows.
Unified Architecture for Local Multimodal Processing
Gemma 4 12B’s most striking design choice is its unified, encoder-free architecture for local multimodal processing. Instead of separate front-end encoders for each modality, audio and image inputs are routed directly into the same language-model backbone that handles text. This reduces extra components that would otherwise consume memory and add latency on laptop-class hardware. Raw 16 kHz audio is split into 40 ms frames and projected into the model’s input space, while images are handled by a 35‑million‑parameter vision embedder that replaces the 27-layer vision transformer stack seen in other medium Gemma 4 variants. The goal is to keep the entire pipeline light enough to stay within a 16GB envelope, so a single local agent can listen, read, reason, and call tools without exhausting shared CPU/GPU memory when running on-device AI models.
On-Device AI Agents, Latency, and Laptop Limits
Google is framing Gemma 4 12B as a workhorse for laptop AI inference, especially for local agents that must answer quickly and work offline. With audio, image, and code support built into the same model, developers can design assistants that move between voice commands, screenshot analysis, and coding help without cloud round trips. Multi-Token Prediction (MTP) variants add another latency angle: drafter components propose multiple upcoming tokens so the main model can confirm more than one token per step, cutting generation time when predictions are accurate. The 256K-token context window aligns with use cases like long debugging sessions, multi-document reasoning, or extended tool-call traces. Still, independent tests must confirm whether a typical 16GB laptop can sustain long multimodal sessions without slowdowns, and how accuracy compares to cloud-first multimodal systems.
Tools, Runtimes, and Where Gemma 4 12B Fits in the Stack
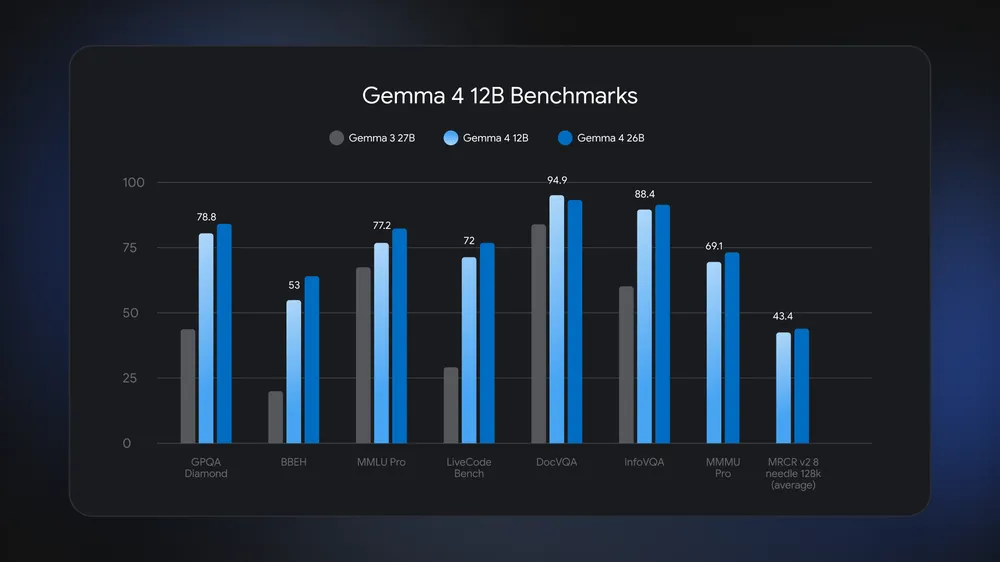
Gemma 4 12B sits between Google’s smaller E4B option and its 26B Mixture of Experts model, targeting developers who need more capability than tiny edge models but still want local multimodal processing. The model can be served locally through LiteRT-LM as an OpenAI-compatible API, allowing tools like Continue, Aider, OpenClaw, Hermes, and OpenCode to swap it in without major changes. Google is also pairing the release with macOS desktop support through Google AI Edge Gallery and Google AI Edge Eloquent, widening deployment paths for local AI agents. Weights and runtimes are available through platforms such as Hugging Face, Kaggle, Ollama, LM Studio, and Docker, giving engineers multiple routes to experiment. Competing open-weight models like Nvidia’s Nemotron 3 Nano Omni and Z.ai’s GLM-4.6V target similar audiences, so meaningful comparisons will depend on shared prompts and standardized laptop benchmarks.