What Gemma 4 12B Is—and Why It Matters
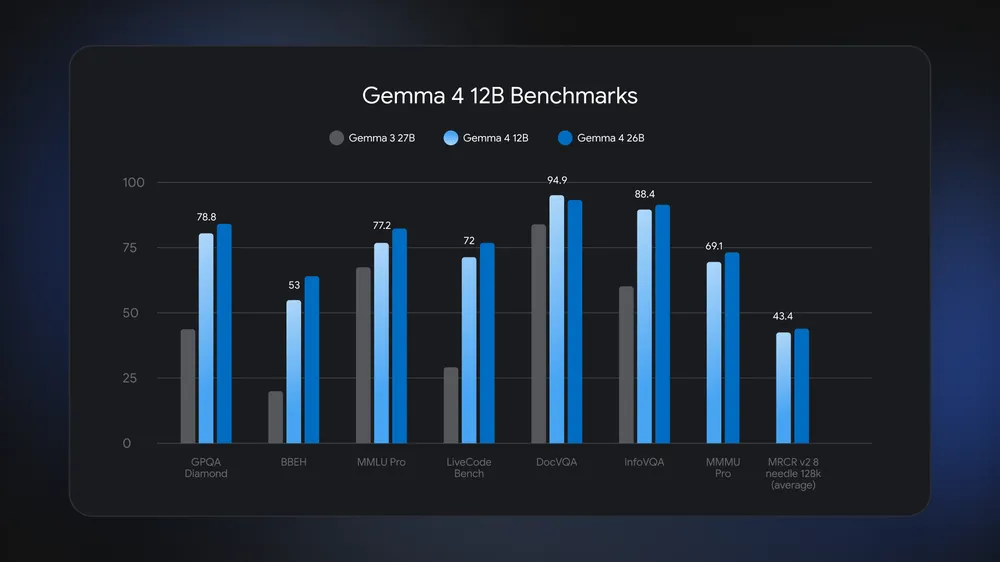
Gemma 4 12B is a 12‑billion‑parameter, open source AI model from Google DeepMind that delivers local multimodal AI—covering text, images, and audio—on ordinary laptops with 16GB of memory, combining near–frontier performance with a compact design that avoids the cloud, reduces hardware demands, and keeps user data on the device. Released on June 3, Gemma 4 12B fills the gap between phone‑class Gemma variants and workstation‑scale models. It nearly matches the larger Gemma 4 26B Mixture of Experts model on benchmarks while clearly beating the older Gemma 3 27B across tests such as GPQA Diamond, MMLU Pro, and DocVQA. By running efficiently on consumer hardware, the Gemma 4 12B model directly answers rising memory costs and the growing demand to run AI on a laptop rather than remote servers.

An Efficient Architecture Built for Local Multimodal AI
The headline feature of Gemma 4 12B is its streamlined architecture for local multimodal AI. Unlike most models that depend on separate vision and audio encoders, Gemma 4 12B feeds non‑text inputs directly into the language backbone. For images, a slim 35‑million‑parameter embedding module splits pictures into 48×48 pixel patches and projects each patch into the model’s hidden dimension with a single matrix multiplication, maintained with positional embeddings. This replaces 27 vision transformer layers and about 550 million parameters in the larger Gemma 4 models, slashing memory and latency. Audio is even more direct: raw 16 kHz waveforms are cut into 40‑millisecond frames and projected into the same vector space as text tokens, with no standalone encoder. This design lets a standard 16GB laptop handle speech recognition, speaker diarization, image understanding, and even video analysis without a data‑center GPU.
Performance Close to 26B, Without Data Center Hardware
Gemma 4 12B aims to deliver near‑26B‑class capability while using far fewer resources. Google says the model runs on any laptop with 16GB of system RAM or VRAM, using roughly half the memory of the 26B Mixture of Experts while staying close on benchmark performance. It also outperforms Gemma 3 27B on demanding tasks like GPQA Diamond, MMLU Pro, and DocVQA. Multi‑Token Prediction (MTP) drafters are enabled by default, a first in the Gemma 4 family. MTP uses spare compute to guess several future tokens at once, increasing generation speed without a quality penalty. In one demo, Gemma 4 12B processed a five‑minute Google I/O keynote, reading 313 video frames at one per second with 70 visual tokens per frame alongside audio. For developers, this means work that previously required a high‑end accelerator can now run on a mid‑range laptop.
Privacy, Local Control, and the Push Beyond the Cloud
By design, Gemma 4 12B lets users run AI on a laptop without sending data to the cloud. That matters for anyone handling confidential documents, offline workflows, or regulated environments where network use is restricted. Inputs such as customer recordings, internal PDFs, or product images can be processed on the device, with no external API calls. This aligns with a broader industry shift toward on‑device AI as memory and cloud demand soar. DRAM prices jumped about 90% in the first quarter of 2026 compared with the previous quarter, and Micron told CNBC at CES it was effectively sold out of memory for 2026. A model capable of agent‑style reasoning, multimodal understanding, and code generation on a 16GB laptop lets teams sidestep both cloud capacity limits and the escalating cost of large‑scale infrastructure.
Open Source AI Models and the New Developer Baseline
Gemma 4 12B is released under the Apache 2.0 license, with weights available on Hugging Face and Kaggle at just under 18GB. That combination of permissive licensing and modest hardware needs lowers the barrier to entry for developers building multimodal applications. According to Google, Gemma 4 models have already passed 150 million downloads, and the 12B variant slots neatly into existing toolchains such as Hugging Face Transformers, vLLM, SGLang, MLX, llama.cpp, and LiteRT‑LM. Developers can run AI on laptop hardware they already own while experimenting with speech‑aware agents, visual document analysis, or video understanding without building a back‑end cluster. Google is also promoting its Google AI Edge stack for macOS, including on‑device apps like the Eloquent dictation tool and a coding app in the Edge Gallery, showing how Gemma 4 12B can anchor consumer‑grade, fully local AI experiences.




