What Gemma 4 12B Is and Why It Matters
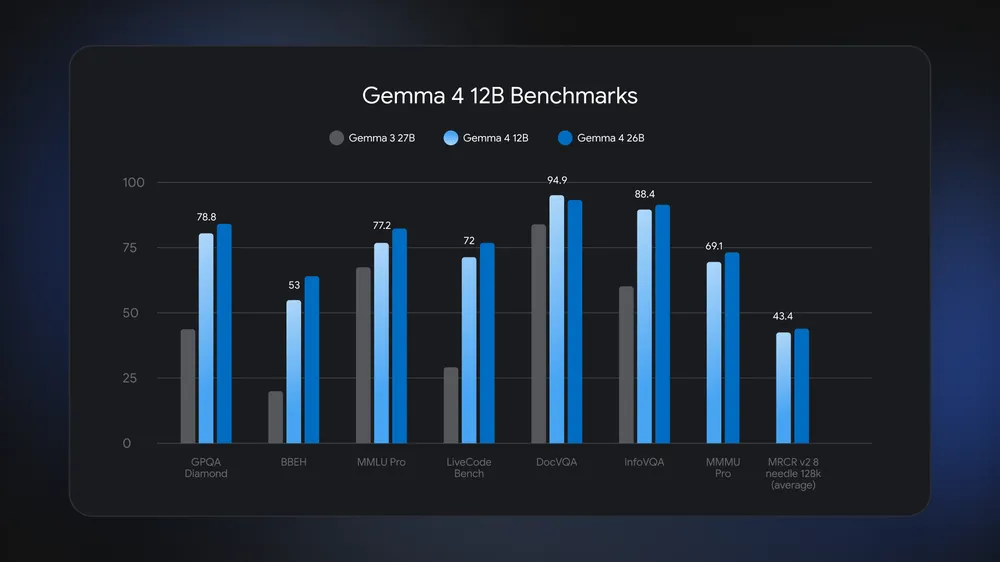
Gemma 4 12B is a 12‑billion‑parameter local AI model from Google designed to run multimodal tasks—text, images, and audio—directly on standard laptops with 16GB of memory, enabling on-device AI without relying on cloud infrastructure for most everyday workflows. Unlike many heavyweight language models, Gemma 4 12B is small enough to fit within roughly 16GB of unified or video memory, yet performs close to the larger Gemma 4 26B and even outperforms older models on benchmarks like DocVQA. The weights, available under the Apache 2.0 license on platforms such as Hugging Face and Kaggle, make it accessible to developers and enthusiasts who want a multimodal AI laptop setup at home or work. This combination of size, openness, and multimodal support turns Gemma 4 12B into a practical gateway for edge AI computing on consumer hardware.

An Encoder-free Architecture for Multimodal AI on a Laptop
Gemma 4 12B’s most important technical choice is its unified, encoder-free architecture, which cuts out the separate vision and audio encoders that usually sit in front of large language models. For images, a slim 35‑million‑parameter embedding module splits visuals into 48×48 pixel patches and projects them directly into the model’s hidden space with a single matrix multiplication. For audio, the model slices 16 kHz waveforms into 40 ms frames (640 samples) and projects them into the same input space as text tokens. This design feeds all modalities straight into the decoder-only transformer backbone, the same advanced decoder structure as Gemma 4 31B Dense, reducing latency and memory fragmentation. According to Google, this approach keeps Gemma 4 12B nearly neck and neck with Gemma 4 26B on benchmarks while consuming roughly half the memory, a balance that is key for on-device AI.

Agentic Workflows and Google AI Edge Integration
Gemma 4 12B is tuned for more than chat: it is built for agentic workflows running entirely on personal machines. Google describes it as “designed to bring agentic, multimodal intelligence directly to your laptop,” and it is tightly integrated with Google AI Edge tools. Through the AI Edge Gallery app and Eloquent on-device voice dictation, users can generate and execute scripts, process data, or create visual insights without leaving their multimodal AI laptop environment. One demo shows the model turning a plain-language request into a Python script that renders a PNG chart of top baby names. Multi-Token Prediction drafters, enabled by default, help use spare compute cycles to predict several future tokens, speeding up text generation. With all modalities sharing the same weights, fine-tuning—via LoRA adapters or full training—can update the entire loop in one pass, making custom local AI models easier to build on edge AI computing platforms.

Practical Benefits for Privacy, Offline Use, and Everyday Users
Running Gemma 4 12B locally on a 16GB laptop changes what everyday users can expect from on-device AI. Instead of sending audio recordings, images, or documents to remote servers, the model processes them on the device, which can help privacy-conscious users keep sensitive data closer to home. Offline operation means AI features continue working during travel, in low-connectivity environments, or inside secured networks. Because Gemma 4 12B approaches the performance of the 26B Mixture of Experts while using about half the memory, tasks like multistep reasoning, document question answering, and autonomous tool execution move from data centers to desks. This makes local AI models practical for developers and non-technical users alike: from coding assistants and meeting transcriptions to visual note-taking and personal research agents. The result is a new class of edge AI computing where powerful, multimodal assistants live on the machines people already own.