What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is Google’s mid-sized, 12‑billion‑parameter multimodal AI model designed to run text, image, and audio workloads locally on standard 16GB laptops without relying on cloud infrastructure or high-end accelerators. By shrinking its memory footprint to under 18GB of weights while preserving near-flagship benchmark scores, the Gemma 4 12B model offers near-26B performance in a form that fits typical consumer hardware. This shift means that multistep reasoning, document question answering, and agent-style workflows that once required data center resources or large desktop GPUs can now execute entirely on-device. For users, that translates into lower latency, better privacy, and fewer hardware upgrades. For developers, it opens a practical middle tier between lightweight mobile models and heavy data center deployments, bringing serious local AI laptop experiences within reach of a far wider audience.

Near-26B Performance in a 16GB-Friendly Package
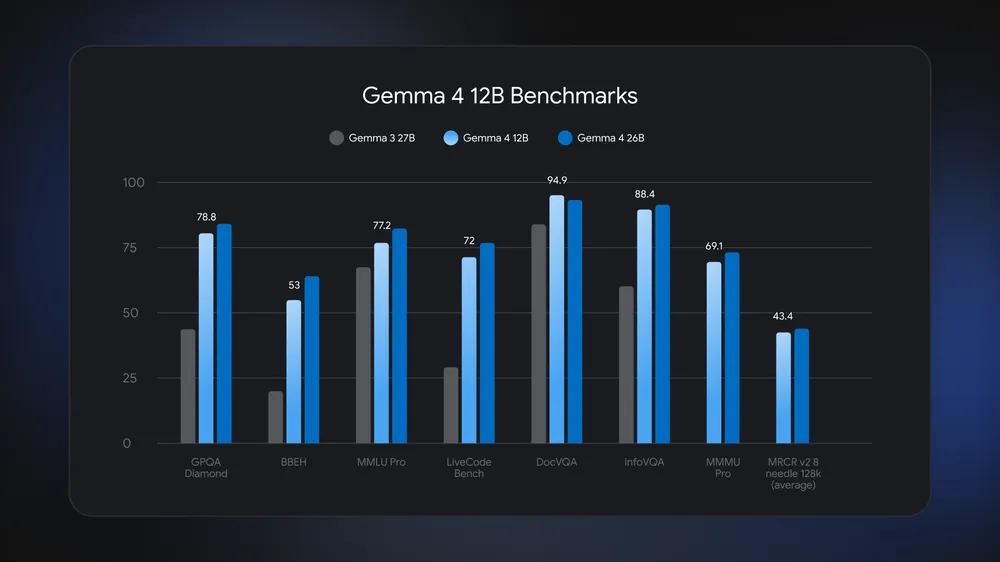
Google positions Gemma 4 12B as a bridge between its mobile-focused E2B and E4B variants and the heavier 26B and 31B models, but performance numbers suggest it punches above its weight. Benchmarks shared by Google show the 12B configuration running neck and neck with Gemma 4 26B, and even surpassing the older Gemma 3 27B on tasks like GPQA Diamond, MMLU Pro, and DocVQA. At the same time, the model uses roughly half the memory of the 26B Mixture-of-Experts design and remains light enough for any machine with 16GB of system RAM or VRAM. This efficiency comes partly from Multi-Token Prediction drafters, enabled by default here, which use spare compute to draft future tokens and speed up text generation. The result is on-device AI inference that feels closer to cloud-scale systems, without the infrastructure overhead.

Unified Architecture and Native Audio: A Different Take on Multimodal AI
Most multimodal AI models bolt separate encoders onto a language backbone to handle non-text inputs, but Gemma 4 12B takes a different path. It feeds images and audio directly into the LLM core, which cuts latency and memory use compared with traditional multimodal AI models. For vision, a compact 35‑million‑parameter embedding module replaces the 27-layer vision transformer stack seen in medium Gemma 4 models, slicing images into 48×48 pixel patches and mapping them into the model’s hidden space with a single matrix multiplication. Audio goes further: instead of a dedicated encoder, raw 16 kHz waveforms are split into 40‑millisecond frames and projected into the same vector space as text tokens. According to Google DeepMind, this unified design delivers native audio support in a mid-sized model for the first time in the Gemma family, enabling speech recognition, diarization, and video analysis entirely on-device.

From Enthusiast LLMs to Practical Local AI Laptops
Community reaction hints at how Gemma 4 12B might shift expectations for local AI laptop setups. Developers on Reddit’s r/LocalLLaMA have called it “one of the most exciting models” in some time, highlighting its native audio support and practical memory demands. The model’s Apache 2.0 license and availability on platforms like Hugging Face and Kaggle make it easy to integrate into open projects and custom applications. While some observers note that coding performance may still lag specialized coding models such as Qwen 3.6 35B or Gemma 4 26B in A3B and A4B variants, Gemma 4 12B is not primarily aimed at topping programming benchmarks. Instead, it focuses on broad, multimodal competence and accessible deployment. As memory prices rise with AI data center demand, this kind of efficient, mid-range model strengthens the case that the future of everyday AI use can be local, private, and offline.