What Gemma 4 12B Is and Why It Matters for Local AI
Gemma 4 12B is a 12‑billion‑parameter, open multimodal AI model from Google designed for local multimodal AI, bringing near‑flagship performance for text, image, and audio understanding to ordinary laptops with 16GB of memory through efficient on-device AI inference. Rather than targeting data centers, the Gemma 4 12B model is sized so it can run natively on consumer hardware that many people already own, cutting dependence on cloud GPUs. According to Google DeepMind, it uses roughly half the memory of the larger Gemma 4 26B while staying close to it on benchmark scores. This positions 12B as the practical middle ground between tiny mobile models and heavyweight desktop or server deployments, turning laptop AI computing into a realistic option for multistep reasoning, document visual question answering, and agentic workflows that previously required much larger models.

Encoder-Free Architecture: How 12B Stays Small but Capable
Most multimodal models bolt separate vision and audio encoders onto a language backbone, increasing memory use and latency. Gemma 4 12B breaks from this by using an encoder-free architecture that feeds visual and audio inputs directly into the LLM backbone. For images, a slim 35‑million‑parameter embedding module splits pictures into 48×48 pixel patches and projects them into the model’s hidden dimension with a single matrix multiplication, instead of a full vision transformer stack with around 550 million parameters. Audio inputs are handled with an even leaner path: raw 16 kHz audio is chopped into 40‑millisecond frames and projected into the same space as text tokens, with no audio encoder at all. This design shrinks the overall footprint while keeping multimodal abilities intact, enabling on-device AI inference that feels closer to larger, encoder-heavy models.

Near-26B Performance on a 16GB Laptop
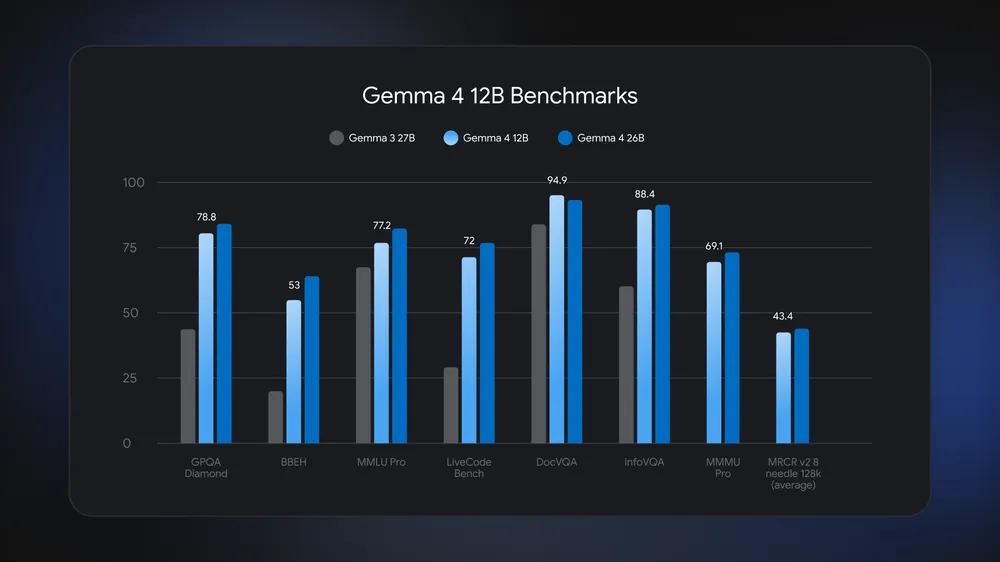
Benchmark data from Google shows the Gemma 4 12B model running neck and neck with the Gemma 4 26B Mixture of Experts on many tasks, even surpassing it on DocVQA, a demanding document visual question answering benchmark. The company also reports that Gemma 4 12B clearly beats the older Gemma 3 27B across tests such as GPQA Diamond, MMLU Pro, and DocVQA. At the same time, it uses about half the memory of the 26B model and fits within 16GB of system RAM or VRAM, so it can execute local multimodal AI workloads on mainstream laptops instead of high-end accelerators. Multi‑Token Prediction drafters, enabled by default for the first time in a Gemma model, further speed up text generation by predicting several future tokens in parallel, helping the smaller network keep pace with larger siblings in real-world interactive use.

Agentic Workflows and Everyday Laptop AI Computing
Because Gemma 4 12B brings strong reasoning and multimodal inputs to local hardware, it opens the door to agentic workflows that run entirely on-device. Developers can build assistants that listen to live audio, watch screen content, read documents, and then autonomously plan and execute multistep tasks without sending data to the cloud. Early community reactions highlight native audio support on a non‑tiny model as a key attraction for such agentic use cases. While some commenters expect that other models may still be better at intensive coding tasks, the Gemma family is described as strong for the broad range of jobs people use a local LLM for, from transcription and summarisation to document analysis and media understanding. That balance of capability and efficiency helps shift laptop AI computing from simple chatbots toward autonomous, multimodal task runners.
Open Weights and the Path to Edge and On-Device Apps
Gemma 4 12B is released under the Apache 2.0 license, with weights available on platforms such as Hugging Face and Kaggle at just under 18GB, which aligns well with its 16GB memory target for on-device AI inference. That licensing and model size make it practical to integrate into local multimodal AI applications and to pair with frameworks such as Google AI Edge for deployment across laptops, desktops, and other capable devices. Developers can experiment with speech recognition, speaker diarisation, code generation, image understanding, and even basic video analysis without provisioning remote infrastructure. At a time when research cited by Northeastern University notes that memory prices jumped roughly 90% quarter over quarter, a model built to “sip RAM instead of guzzle it” provides a timely foundation for more affordable, privacy-friendly edge intelligence.