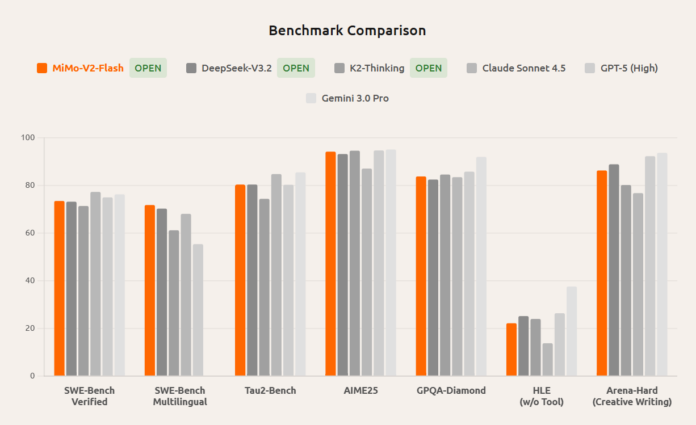
What MiMo-V2.5-Pro UltraSpeed Mode Is and Why It Matters
Xiaomi’s MiMo-V2.5-Pro UltraSpeed mode is a GPU optimization feature that lets the company’s trillion-parameter large language model reach more than 1,000 tokens per second on standard graphics cards, making high-throughput LLM inference speed available without expensive enterprise accelerators. UltraSpeed builds on MiMo-V2.5-Pro, an omnimodal model with 1.02 trillion parameters and a million-token context window designed for complex, agent-style tasks. In its regular configuration, MiMo-V2.5-Pro typically runs at around 60–80 tokens per second for demanding workloads, while the lighter MiMo-V2.5 variant reaches roughly 100–150 tokens per second. The new mode raises model throughput by around 10x compared with standard API access, according to Xiaomi’s claims, turning what was already a fast system into one that can stream text far quicker than the fastest human can read. This shift reframes what developers can expect from real-time LLM inference on commodity hardware.
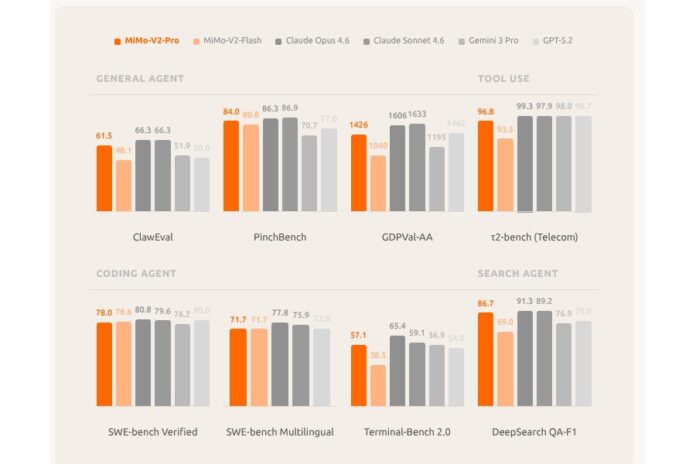
How Xiaomi Hit 1,000+ Tokens Per Second on Standard GPUs
Xiaomi says UltraSpeed is the result of an “ultimate co-design” between the MiMo-V2.5-Pro model and its serving stack, co-developed with TileRT. The company had already experimented with speed-focused designs: MiMo-V2-Flash, a 309-billion-parameter Mixture-of-Experts model, hit 150 tokens per second at launch and introduced multi-token prediction so the system could generate and validate several tokens in parallel. UltraSpeed extends this direction by pushing a one-trillion-parameter model to break the 1,000 tokens-per-second barrier on general-purpose GPUs, rather than on specialised accelerators. According to Xiaomi, UltraSpeed delivers “roughly 10 times faster output than standard MiMo-V2.5-Pro API access,” suggesting aggressive kernel-level GPU optimization, pipeline parallelism, and caching strategies aimed at squeezing more useful computation out of the same hardware. The result is high model throughput that can keep up with or exceed real-time interaction in many applications.
Cost, Trade-Offs, and the June UltraSpeed API Trial
The speed gains of UltraSpeed come with a higher API price and capacity limits. For normal access, MiMo-V2.5-Pro charges 0.025 yuan per million tokens on a cache hit, 3 yuan on a cache miss for input, and 6 yuan per million tokens for output. Xiaomi describes UltraSpeed as a “3x price increase” but claims it offers a “10x output experience,” effectively trading higher per-token cost for lower latency and higher model throughput. Token Plans are not supported for UltraSpeed, and Xiaomi is gating the feature through an application-based trial between June 9 and June 23, 2026. Approval is not guaranteed, with priority given to enterprises and professional developers that can show real business needs. Those approved receive a two-week chat experience, capped by queue and usage limits so the shared high-speed GPU pool remains usable.
What UltraSpeed Means for Accessible LLM Inference
By passing 1,000 tokens per second on standard GPUs, MiMo-V2.5-Pro UltraSpeed changes expectations about what is possible without specialised hardware. Developers who previously needed to rent or buy enterprise accelerators to reach low-latency, frontier-class performance can start to prototype on more accessible GPU fleets. Combined with MiMo’s history of open and competitive models—from MiMo-7B’s strong reasoning scores to MiMo-V2-Flash’s low-cost, high-speed inference—UltraSpeed signals a push toward practical speed improvements that cut waiting time for end users and lower operational costs when amortised across high-traffic workloads. The limited June API trial matters because it allows teams to benchmark tokens per second in real applications, measure cost-performance trade-offs, and understand how UltraSpeed behaves under production-like load. If Xiaomi’s claims hold up in independent testing, UltraSpeed-style GPU optimization could become a template for other LLM providers targeting accessible, high-throughput inference.





