
From Benchmarks to Business: Why AI Inference Speed Now Matters
AI inference speed is the rate at which a model processes and generates tokens per second during prediction time, and it has become a decisive factor in whether language models feel instant enough for everyday tools or stall out under real workloads, shaping both user experience and infrastructure cost. The fastest AI models are no longer a niche leaderboard hobby; they now affect which assistants teams keep open all day and which they abandon. As the Artificial Analysis index shows, token throughput varies widely across leading systems, with some models outputting over 300 tokens per second while others lag far behind. This gap turns into a tangible difference between a smooth chat window and a spinning cursor. As companies track LLM performance benchmarks, the metric is evolving from “how smart is the model?” to “how fast can it respond at scale without breaking the budget?”.
Xiaomi MiMo-V2.5-Pro: Crossing the 1,000 Tokens Per Second Barrier
Xiaomi’s MiMo-V2.5-Pro in UltraSpeed mode is a clear signal that raw tokens per second has become a headline feature. The 1‑trillion‑parameter model, co-designed with TileRT, runs on general-purpose GPUs while “breaking the 1,000 tokens-per-second generation barrier,” a step change from the MiMo family’s earlier numbers. MiMo-V2-Flash was already quick at 150 tokens per second, fast enough that the AI generated text faster than a human could read or speak. UltraSpeed mode raises that limit by around 10x compared with standard MiMo-V2.5-Pro API access, directly targeting high-throughput workloads such as code generation or long-form drafting. This performance bump is priced as a premium service: Xiaomi states that MiMo-V2.5-Pro-UltraSpeed carries a 3x price increase over the regular API, reflecting how high-speed inference resources are now scarce, valuable infrastructure rather than an optional extra.
Parallel Retrieval: Databricks Turns Latency into a Design Problem
Inference speed is not only about how fast tokens fall out of a decoder; it is also about how quickly a system can find the right context. Databricks’ Agent Bricks Knowledge Assistant shows this with Instructed-Retriever-1, a retrieval-specialized model designed for parallel test-time scaling. According to Databricks, “answer generation time has dropped by 2x, and search time has dropped by more than 3x, bringing Time To First Token (TTFT) to around two seconds.” Instead of sequential agent loops, the system fans out query and filter generation in parallel, then merges and reranks results. A multi-pivot groupwise reranker compares evidence in context while keeping latency low. These design choices move the bottleneck away from slow, step-by-step tool use and toward high-throughput context selection, which is key for enterprise workloads where long chains of knowledge lookups can otherwise dominate response time.
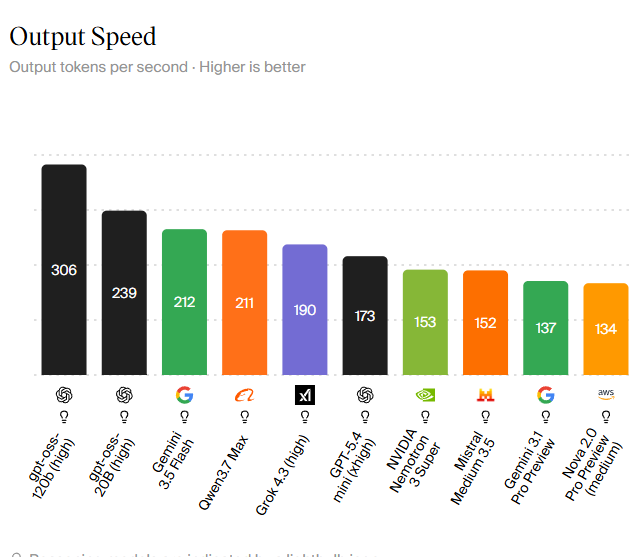
Throughput, TTFT, and the New LLM Performance Benchmarks
As more models boast headline speeds, LLM performance benchmarks are shifting from accuracy-only charts to multi-metric scorecards that highlight Time To First Token and sustained throughput. Data from the Artificial Analysis index places models such as GPT-oss 120B (high tier) at 306 tokens per second, with other leading systems like Gemini 3.5 Flash and Qwen3.7 Max clustered around the 200–212 tokens-per-second range. These figures define what feels snappy in interactive tools: sub‑second TTFT for simple prompts, and hundreds of tokens per second for longer answers. At higher tiers, users are starting to compare speed-per-dollar rather than speed alone. Meanwhile, breakthroughs such as MiMo-V2.5-Pro UltraSpeed’s four‑digit tokens-per-second output suggest that we are entering a phase where specialized throughput optimization and system co-design matter as much as model size or training data volume.
What Faster Inference Unlocks: Agents, Workflows, and Beyond
Once generation and retrieval are fast enough, new product patterns become practical. Long-running AI agents that call tools repeatedly can feel responsive if each search step takes a couple of seconds instead of ten. Parallel retrieval, as in Instructed-Retriever-1, allows complex queries across large enterprise indexes without forcing people to wait through slow, serial reasoning chains. Ultra-high tokens-per-second rates open the door to near-real-time code editing, multi-document summarization, and continuous monitoring workflows where models stream updates rather than respond in one big block. At the infrastructure level, model throughput optimization reduces queueing and makes better use of GPUs, while also clarifying the trade-offs between speed and cost. In this new speed war, competitive advantage will belong to teams that design around end-to-end latency, not just model quality, and that treat inference speed as a core product feature rather than a backend detail.





