What Gemma 4 12B Is and Why It Matters
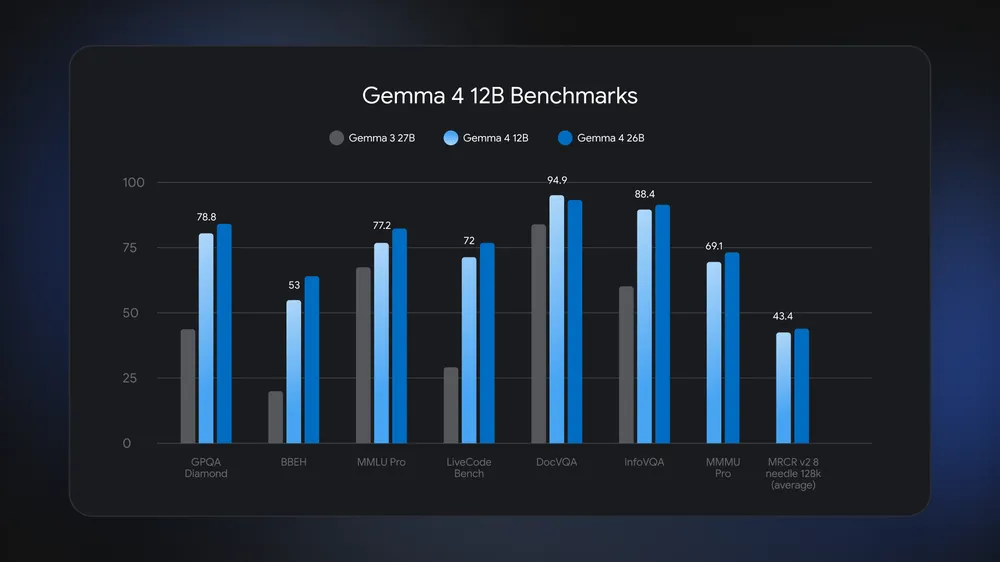
Gemma 4 12B is a 12‑billion‑parameter local multimodal AI model from Google DeepMind that runs on laptops with 16GB of memory, handling text, images, audio, code, and tool calls without requiring separate encoders or dedicated accelerators. Instead of being locked to data centers, Gemma 4 12B brings on-device AI processing to ordinary machines, using about half the memory of the larger Gemma 4 26B model while staying close on key benchmarks. The weights, available under an Apache 2.0 license, arrive as an open-weights model design so developers can download, fine-tune, and integrate the system directly into desktop apps or local AI agents. This mid-sized model fills the gap between phone-focused variants and workstation-class models, giving everyday users access to laptop AI inference that can handle multistep reasoning, agent-style workflows, and multimodal understanding entirely on their own hardware.

Encoder-Free Architecture: Multimodal AI Without the Bulk
Most multimodal systems bolt separate vision and audio encoders onto a language model, which increases parameters, latency, and memory use. The Gemma 4 12B model takes a different path with an encoder-free architecture that handles non-text inputs in a lean way. For images, a lightweight 35‑million‑parameter embedding module splits pictures into 48×48 pixel patches, then uses a single matrix multiplication to map each patch into the model’s hidden space, guided by positional embeddings to keep spatial layout. This replaces 27 vision transformer layers and roughly 550 million parameters used in larger Gemma 4 models. Audio goes even further: raw 16 kHz waveforms are sliced into 40‑millisecond frames and projected straight into the same vector space as text tokens, without any separate audio encoder. The result is lower memory overhead and faster multimodal processing that fits within 16GB RAM limits.
Running Images, Audio, Code, and Tools on a 16GB Laptop
By cutting encoders and shrinking the vision module, Gemma 4 12B keeps its memory footprint small enough for on-device AI processing on standard 16GB laptops. According to Google, “Gemma 4 12B runs locally on any laptop with 16GB of system RAM or VRAM,” while using roughly half the memory of the 26B Mixture of Experts model. Despite that, it stays close on benchmarks and surpasses the older Gemma 3 27B on tests such as GPQA Diamond, MMLU Pro, and DocVQA. The model supports native audio tasks like speech recognition and speaker diarization, alongside code generation, image understanding, and video analysis, all within a single multimodal backbone. In one demonstration, it processed a five‑minute Google I/O keynote clip at one visual frame per second plus audio, showing that laptop AI inference can now cover full multimedia streams, not only text chat.
LiteRT-LM and Multi-Token Prediction: Speeding Up Local Inference
Multimodal support alone is not enough; laptop users also need fast responses. Gemma 4 12B ships with Multi-Token Prediction (MTP) drafters enabled by default, which use spare compute to guess several future tokens, then let the main model verify them. Google’s LiteRT-LM framework adds native support for these MTP drafters, providing up to 2.2× faster inference for some Gemma 4 variants while also improving prefill and decode performance compared with other runtimes. LiteRT-LM builds on LiteRT (formerly TensorFlow Lite) and focuses on keeping memory local: both the MTP drafter and main model can run on the same GPU, sharing a KV cache without costly data transfers. Optimized pipelines, quantization, and accelerated kernels further reduce latency. Together, Gemma 4 12B and LiteRT-LM give developers a high-performance path to local multimodal AI that feels responsive even on constrained hardware.

Open Weights and Custom AI Agents on Personal Devices
Because Gemma 4 12B is an open-weights model under an Apache 2.0 license, developers can download it from platforms like Hugging Face and Kaggle, then adapt it for their own local multimodal AI workflows. The weights are just under 18GB, making them practical to host on consumer hardware while still offering strong performance close to the 26B model. This openness lets teams build laptop AI inference pipelines that never leave the device: privacy-sensitive assistants, offline transcription tools, local code copilots, and multimodal AI agents that call tools or process documents without sending data to external servers. With a single encoder-free architecture for text, audio, and images, plus performance enhancements from Multi-Token Prediction and LiteRT-LM, Gemma 4 12B turns a standard 16GB laptop into a capable multimodal development platform that ordinary users and small teams can control end to end.




