What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is an open-weights, encoder-free multimodal AI model that runs advanced language, vision, and audio workloads directly on laptops with 16GB of memory, enabling local multimodal AI experiences that previously needed far larger cloud models or specialised hardware. Designed as a mid-sized member of the Gemma 4 family, the Gemma 4 12B model fills the gap between phone-ready variants and larger 26B and 31B models. Google reports that Gemma 4 12B achieves benchmark performance close to the 26B Mixture-of-Experts model while using roughly half the memory footprint. Because the weights are released under an Apache 2.0 licence and are available on platforms like Hugging Face and Kaggle, individual developers, researchers, and professionals can download and run the model locally without a network connection, enabling on-device AI processing for text, images, and audio.

Inside the Encoder-free Architecture
Traditional multimodal systems bolt separate vision and audio encoders onto a language model, adding stages that increase latency and memory use. Gemma 4 12B replaces this with a unified, encoder-free architecture: vision and audio inputs flow straight into a single decoder-only transformer, the same advanced decoder structure used in the Gemma 4 31B Dense model. For images, a lightweight 35M-parameter vision embedder replaces the heavier 27-layer vision transformer seen in other Gemma 4 medium models by projecting 48×48 pixel patches into the LLM’s hidden space with one matrix multiplication and factorised X–Y positional lookups. For audio, the model slices 16 kHz waveforms into 40 ms frames and linearly projects them into the input space, removing the need for a separate audio encoder. Using shared weights for all modalities also simplifies fine-tuning: one adapter pass can update the entire multimodal loop.

Running Local Multimodal AI on a 16GB Laptop
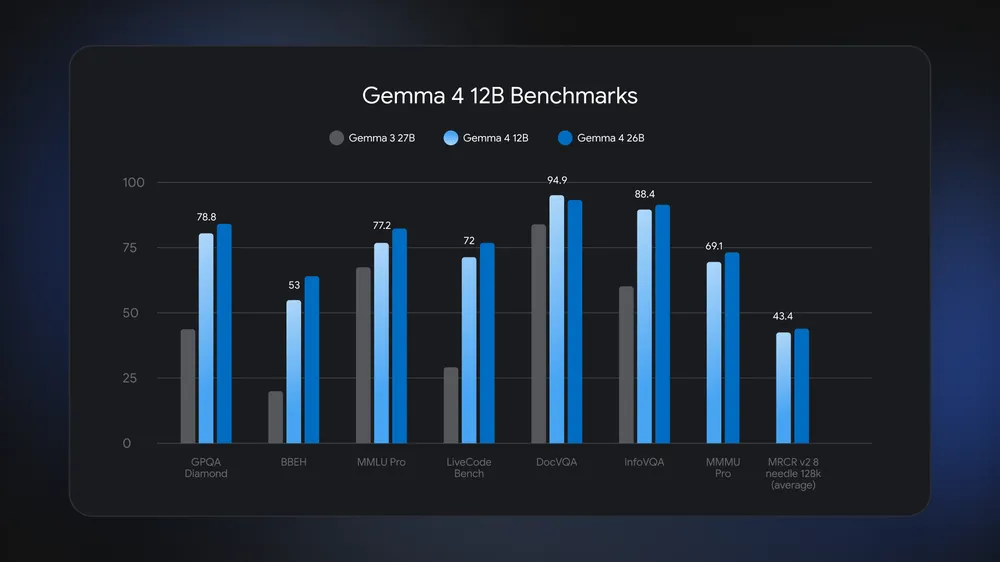
Gemma 4 12B is built for laptop AI workloads rather than high-end data centre setups. The 11.95-billion-parameter model is optimised to run on machines with 16GB of VRAM or unified memory, which covers a wide range of current consumer laptops. According to Google, Gemma 4 12B uses about half the memory of the 26B Mixture-of-Experts model while staying close to it on standard benchmarks, and it clearly outperforms Gemma 3 27B on tests such as GPQA Diamond, MMLU Pro, and DocVQA. Because inputs like images and audio pass straight into the language model, there is less memory fragmentation than in multi-encoder designs. Multi-Token Prediction (MTP) drafters are enabled by default, using spare compute to predict several future tokens at once and reduce response latency, which keeps on-device AI processing responsive even on modest hardware.
Agentic Workflows Without the Cloud
By combining efficient multimodal design with laptop-ready memory needs, Gemma 4 12B makes local multimodal AI practical for agentic workflows that once relied on cloud endpoints. Applications can use the model as a primary local engine, keeping sensitive documents, images, and audio on-device while still gaining advanced reasoning. For example, a financial analyst could run an agent that summarises confidential quarterly reports stored locally, or a field engineer could capture photos of equipment and have a local system interpret them and retrieve related notes from a local database. In both cases, the system can keep working when offline and avoid network latency. Because the weights are open and Apache 2.0 licensed, developers can integrate the Gemma 4 12B model into their own tools, add retrieval from private data, and build custom multimodal agents that act over local files, sensors, and applications.
Building Local Apps with Google AI Edge
Gemma 4 12B integrates with Google AI Edge tools to create a practical stack for local multimodal AI. The Google AI Edge Gallery macOS application lets developers download, manage, and run models such as Gemma 4 12B through a graphical interface, turning natural language instructions into executable scripts or code on the same machine. Google AI Edge Eloquent, a reference app for offline voice dictation and text editing, shows how on-device AI processing can match cloud transcription services while keeping audio private. Gemma 4 12B is also supported in LiteRT-LM for more embedded-style deployments. Together, these tools form a development environment for experimenting with local multimodal AI, from generating webpage layouts and data visualisations to orchestrating autonomous data processing flows, all powered by the same encoder-free architecture running directly on consumer hardware.




