What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is an open-weights, encoder-free multimodal AI model that lets you run advanced text, image, and audio workloads locally on a standard laptop with 16GB of memory, delivering performance near much larger systems while keeping latency low and data on your device. Unlike cloud-only AI, this local multimodal AI model is designed for “agentic” tasks: multi-step reasoning, tool use, and workflows that react to documents, screenshots, or voice input. With 11.95 billion parameters and weights released under the Apache 2.0 license, the Gemma 4 12B model slots between phone-sized Gemma 4 variants and the larger 26B Mixture of Experts, using roughly half the memory of the 26B while staying close on benchmarks. According to Google, Gemma 4 models have already passed 150 million downloads, showing strong interest in models that can run AI on laptop hardware people own today.

Encoder-Free Architecture: How It Cuts Memory and Latency
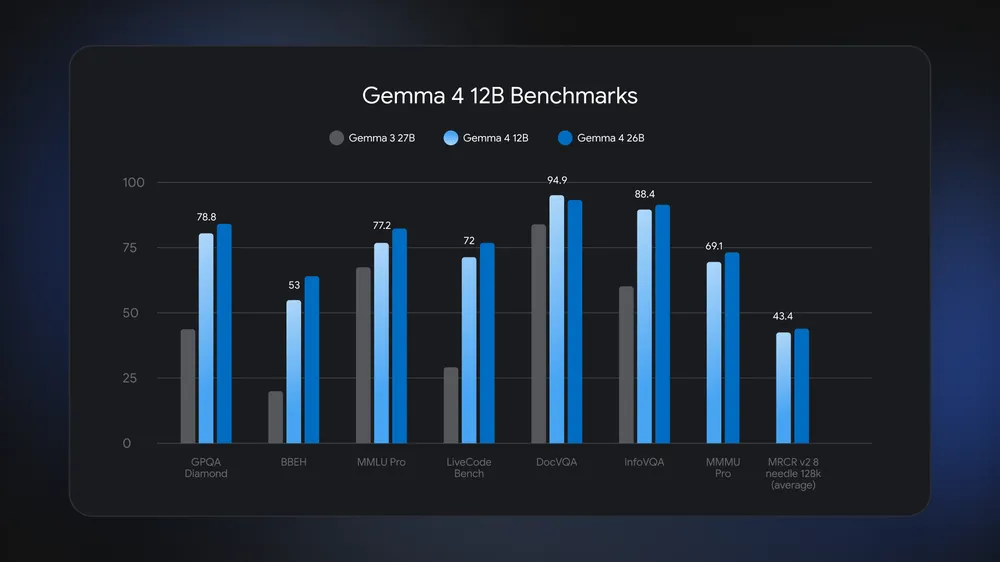
Most multimodal systems rely on separate encoders to pre-process images and audio before handing them to a language model. That extra stage costs memory, compute, and time. Gemma 4 12B takes a different path: it uses an encoder-free architecture where vision and audio inputs feed directly into the LLM backbone. For vision, a compact embedding module of about 35 million parameters replaces a large dedicated encoder, shrinking the memory footprint while keeping rich representations. This design is central to making local multimodal AI practical on 16GB laptops: fewer components to load, fewer parameters to keep in RAM, and a simpler execution graph. Google reports that Gemma 4 12B uses about half the memory of the 26B model while staying close in performance on benchmarks like GPQA Diamond, MMLU Pro, and DocVQA, and it clearly beats the older Gemma 3 27B on those same tests.
Running AI on Your Laptop: Privacy, Latency, and New Workflows
Because the Gemma 4 12B model runs fully on-device with 16GB of VRAM or unified memory, you can run AI on laptop hardware without sending data to a server. That eliminates network latency and cloud dependencies, which matters for confidential or time-critical tasks. An analyst can summarize internal reports stored locally; a field engineer can analyze equipment photos and cross-reference a local knowledge base. In both cases, sensitive data never leaves the machine. Google’s AI Edge Gallery for macOS makes it easier to manage and run local models, while the AI Edge Eloquent reference app highlights offline dictation and text editing that competes with cloud transcription. Instead of a thin client calling remote endpoints, applications can treat Gemma 4 12B as a first-class local engine, staying functional offline and cutting the ongoing costs tied to remote inference and token usage.
LiteRT-LM Inference and Multi-Token Prediction Speedups
Architecture alone is not enough; local multimodal AI also depends on tight runtime optimization. LiteRT-LM, built on the LiteRT (formerly TensorFlow Lite) foundation, provides a specialized orchestration layer for Gemma 4 models across Android, iOS, and the web. It now includes native support for Gemma 4 Multi-Token Prediction drafters, which can deliver up to 2.2x faster inference in some configurations. According to Google, LiteRT-LM reaches 1.8x to 3.7x better prefill and decode performance than frameworks like llama.cpp, MLX, Cactus, and ONNX in its benchmarks. The runtime keeps both the main model and the MTP drafter on the same hardware IP, sharing KV cache and activations to avoid slow data transfers. This speculative decoding approach allows the drafter to propose several future tokens at once, which the main Gemma 4 12B model can verify efficiently, cutting end-to-end response time for interactive workloads.

What Developers Can Build with Local Multimodal AI
Gemma 4 12B’s combination of encoder-free architecture and fast LiteRT-LM inference opens a wide range of laptop-scale applications. Developers can build offline copilots that read PDFs, screenshots, and diagrams alongside text prompts, or voice-driven tools that transcribe and edit content without a network connection. Agentic workflows become viable on personal machines: a local assistant that plans research, reads company handbooks, and drafts reports; or a technician app that inspects images, explains failures, and surfaces relevant manuals from local storage. Because the model ships with MTP drafters enabled by default, these experiences feel responsive even on consumer hardware. With open weights under Apache 2.0 and broad ecosystem support from platforms like Hugging Face and Kaggle, Gemma 4 12B gives teams a practical way to adopt local multimodal AI today, without waiting for specialized accelerators or custom hardware deployments.




