What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is a 12‑billion‑parameter local multimodal AI model that runs directly on consumer laptops, processing text, images, and audio through a single decoder‑only transformer without separate encoders so it can deliver on-device AI reasoning, perception, and agentic workflows without needing cloud infrastructure. Unlike many large models that demand data center GPUs, Gemma 4 12B is sized for laptops with 16GB of RAM or VRAM, making laptop AI inference practical for developers and power users. Google positions it between phone‑class E2B/E4B variants and the heavier 26B and 31B models, matching much of their capability at roughly half the memory footprint of the 26B Mixture of Experts. With open weights under an Apache 2.0 license, it gives individuals and teams a way to customize multimodal assistants, tools, and agents that run entirely on local hardware.

Encoder-Free Architecture: One Backbone for Text, Images, and Audio
At the core of Gemma 4 12B is an encoder-free architecture that treats all modalities as inputs to the same language backbone. Most local multimodal AI systems route images and audio through separate encoders, which adds layers, parameters, and latency before the language model can reason about them. Gemma 4 12B drops those modules and replaces them with a slim vision embedder plus a direct audio projection. For vision, a 35‑million‑parameter embedder slices images into 48×48 pixel patches and projects them into the hidden dimension with a single matrix multiplication, instead of the 27‑layer vision transformer and roughly 550 million parameters used in larger Gemma 4 models. Audio is even more direct: raw 16 kHz waveforms are cut into 40‑millisecond frames and projected into the same token space as text. This unified path simplifies the model, reduces memory use, and keeps multimodal training and fine‑tuning consistent.

Laptop-Friendly Performance and Agentic Workflows
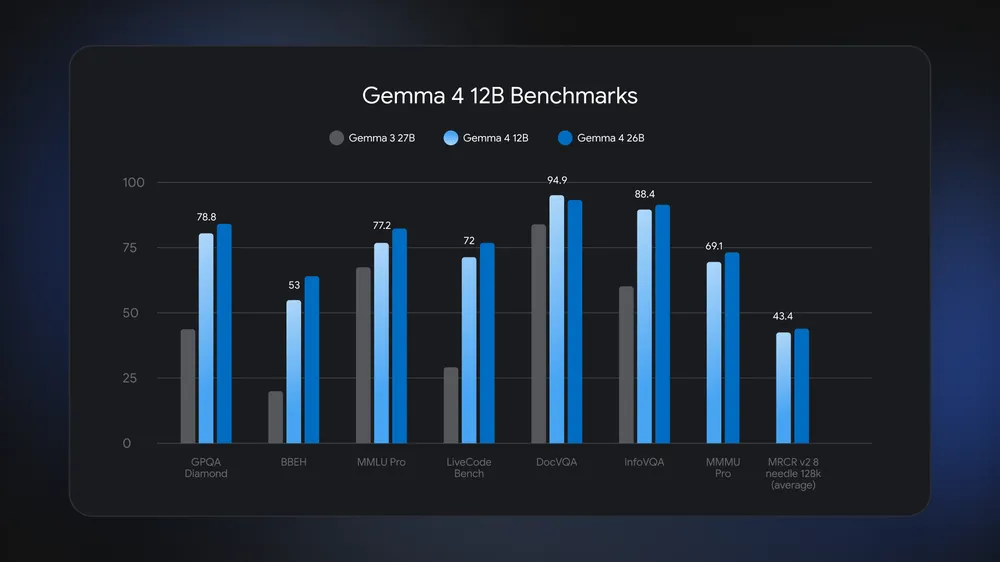
Gemma 4 12B is engineered so laptop AI inference stays usable without high‑end accelerators. According to Google, “Gemma 4 12B runs locally on any laptop with 16GB of system RAM or VRAM,” while using about half the memory of the 26B Mixture of Experts model yet staying close on standard benchmarks. This balance makes it practical to run advanced local multimodal AI tasks like document reasoning with images, code generation from voice, or video understanding on everyday hardware. The model inherits the advanced decoder structure of the Gemma 4 31B dense variant and ships with Multi‑Token Prediction drafters turned on by default, so it can predict several future tokens in parallel and cut latency. That responsiveness is key for agentic workflows, where the model must plan, call tools, and react to user input in near real time without sending data to remote servers.
On-Device Agents and Google AI Edge Integration
Gemma 4 12B is designed to power on-device AI agents that can observe, decide, and act using local resources. Google describes it as “designed to bring agentic, multimodal intelligence directly to your laptop,” with support for tasks like speech recognition, speaker diarization, code generation, image understanding, and even video analysis from sequences of frames and audio. Integrated with Google AI Edge tools, developers can build and experiment locally, from autonomous data processing pipelines to scripts that generate visual insights or webpages. For example, the AI Edge Gallery app uses Gemma 4 12B to turn natural language into executable scripts such as Python programs that render charts. Because text, image, and audio tokens share the same backbone, adapters like LoRA can update the entire multimodal loop in a single pass, which simplifies fine‑tuning custom on-device AI agents for edge computing scenarios.
Open Weights and Practical Local Multimodal AI Development
One of the most important aspects of Gemma 4 12B is that it is an open‑weights model released under the Apache 2.0 license, with downloads available on platforms like Hugging Face and Kaggle. The weights are just under 18GB, so developers can store and load them comfortably on typical laptops. This licensing and size combination means teams can build local multimodal AI applications without cloud infrastructure, keeping sensitive audio, images, and text on-device. Using existing harnesses such as LiteRT‑LM, developers can start OpenAI‑compatible servers from Gemma 4 12B and plug it into existing tools, IDE integrations, or chat interfaces. Because the encoder-free architecture routes all modalities through the same transformer, any fine‑tuning or adapter training improves the full multimodal behavior. Together, these properties make Gemma 4 12B a practical base for customized agents, copilots, and domain‑specific assistants that run entirely on local hardware.