What Gemma 4 12B Is and Why It Matters for Local AI
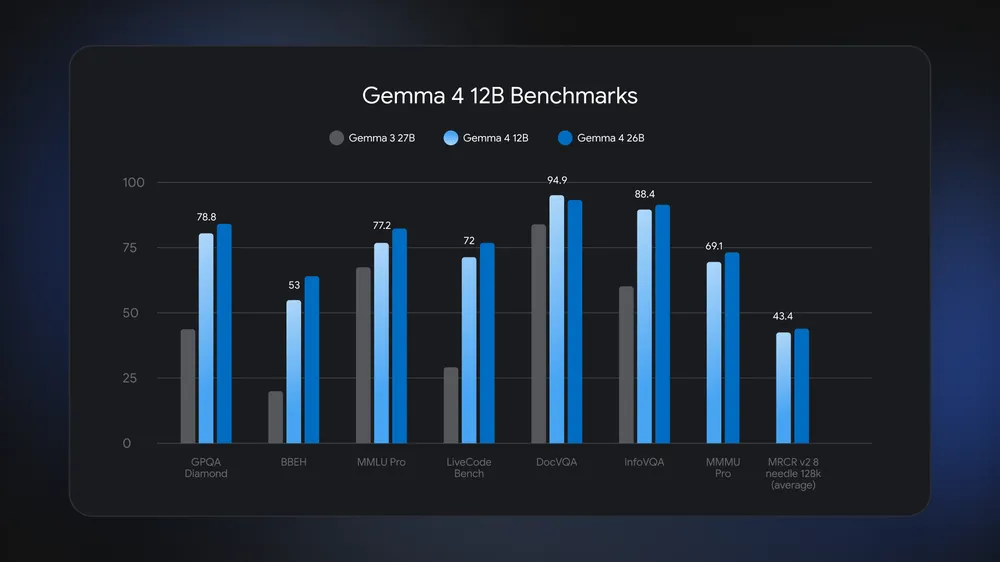
Gemma 4 12B is a 12‑billion‑parameter open‑weights multimodal AI model that runs text, code, images, and audio on ordinary laptops with 16GB of memory, bringing local AI models and on-device AI inference to users without requiring specialized accelerators. Google DeepMind designed this model to sit between phone‑class and workstation‑class systems, filling the gap between earlier Gemma 4 releases. It uses roughly half the memory of the larger Gemma 4 26B while staying close to it on benchmarks, and it clearly beats the older Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA. Because the weights are released under an Apache 2.0 license and distributed through platforms like Hugging Face and Kaggle, Gemma 4 12B fits neatly into the growing ecosystem of open-source AI models that developers can inspect, fine‑tune, and integrate into local AI agents.

Unified, Encoder-Free Multimodal Architecture Explained
Traditional multimodal AI models bolt separate vision and audio encoders onto a language backbone, which adds latency, parameters, and memory. Gemma 4 12B removes those encoders and feeds multimodal data directly into the core model, making multimodal AI laptop setups less complex and more efficient. For images, a slim 35‑million‑parameter embedding module slices inputs into 48×48 pixel patches and projects each patch into the model’s hidden dimension with a single matrix multiplication, replacing 27 vision transformer layers and about 550 million parameters used in other Gemma 4 variants. Positional embeddings preserve spatial layout, so image structure remains intact. Audio is even more direct: raw 16 kHz waveforms are cut into 40‑millisecond frames and projected into the same vector space as text tokens without a separate encoder. This unified design lowers memory requirements and lets Gemma 4 12B handle speech recognition, speaker diarization, image understanding, video analysis, and code generation in a single on-device AI inference pipeline.
Real-World Performance: Benchmarks and Multimodal Tasks
Gemma 4 12B is aimed at local AI agents that have to process complex, mixed‑media workloads without cloud support. Google reports that it “runs on any laptop with 16GB of system RAM or VRAM” while using about half the memory of the 26B Mixture of Experts model. In benchmarks, it trails that 26B sibling slightly but still beats Gemma 3 27B on demanding evaluations like GPQA Diamond, MMLU Pro, and DocVQA, which cover reasoning, knowledge, and document understanding. In practice, this means a multimodal AI laptop can handle long documents, detailed code tasks, or visual question answering without offloading to servers. One demo shows the model processing a five‑minute keynote clip, reading 313 video frames (one per second) with 70 visual tokens per frame alongside audio. These capabilities make Gemma 4 12B suitable for offline transcription, meeting summarization with slides, basic video analysis, and local development assistants built on open-source AI models.
LiteRT-LM and Multi-Token Prediction: Speeding Up Local Inference
Fast responses are essential when you move from cloud systems to local AI models, and this is where LiteRT-LM and Multi-Token Prediction (MTP) matter. Gemma 4 12B is the first mid‑sized Gemma with MTP enabled by default, using lightweight “drafters” that guess several future tokens in parallel while the main model runs. According to Google, LiteRT-LM’s MTP support delivers up to 2.2× faster decoding for Gemma 4 E4B and 1.6× for E2B, and it reports 1.8× to 3.7× faster prefill and decode performance than frameworks like llama.cpp, MLX, Cactus, and ONNX. LiteRT-LM builds on LiteRT (formerly TensorFlow Lite) with an orchestration layer tuned for large language models, optimized CPU/GPU pipelines, and memory‑local execution of both the primary model and the MTP drafter. For developers building local AI agents, this means smoother on-device AI inference, lower latency, and longer conversations without recomputing large contexts thanks to KV cache session management.

How to Get Started Running Gemma 4 12B Locally
To run Gemma 4 12B on your own multimodal AI laptop, start by confirming that you have at least 16GB of system RAM or VRAM. Download the open weights from platforms such as Hugging Face or Kaggle; the full checkpoint is under 18GB, but quantized variants will better fit consumer hardware. Next, choose a runtime that supports Gemma 4, such as LiteRT-LM, which is adding Swift and JavaScript APIs alongside Kotlin and C++. These runtimes handle quantization, optimized kernels like XNNPACK, and Multi-Token Prediction under the hood. Once configured, you can script local AI agents that combine text, images, audio, and code: for example, transcribing and summarizing meetings, inspecting screenshots, annotating documents, or helping write and debug code. Because Gemma 4 12B is an open-source AI model under Apache 2.0, teams can fine‑tune it for domain‑specific tasks while keeping user data on-device.