What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is an open-weights, 12‑billion‑parameter local multimodal AI model from Google that can run entirely on a laptop with 16GB of RAM or unified memory, handling text, images, audio, code, and tool calls without needing an internet connection or specialised AI hardware. Unlike cloud-only systems, Gemma 4 12B is designed for laptop AI inference, so you can run AI offline for tasks such as summarising documents, transcribing speech, or analysing screenshots. Google positions this model between its phone‑class Gemma variants and larger workstation‑class models, filling the gap for everyday machines. According to Google DeepMind, Gemma 4 12B “runs on any laptop with 16GB of RAM” and still trails the larger Gemma 4 26B Mixture of Experts model only slightly in benchmarks. This balance makes it practical for developers, students, and professionals who want capable local multimodal AI without a server.

How the Encoder-Free Design Enables Local Multimodal AI
Most multimodal AI systems rely on separate encoders for vision and audio, which increases memory use and latency on laptops. Gemma 4 12B takes a different path: it routes image, audio, and text inputs directly into the same language-model backbone. For images, a lightweight 35‑million‑parameter vision embedder splits them into 48×48 pixel patches and projects them into the model’s hidden space with a single matrix multiplication instead of using 27 vision transformer layers and roughly 550 million parameters. For audio, raw 16 kHz waveforms are chopped into 40‑millisecond frames and projected straight into the same space as text tokens. This unified, encoder‑free design shrinks the computational footprint so laptop AI inference becomes realistic on machines with 16GB memory. It also allows mixed sessions where the Gemma 4 12B model can listen, read screenshots, write code, and call tools within one continuous context.
Running Gemma Models Offline with Google AI Edge Gallery
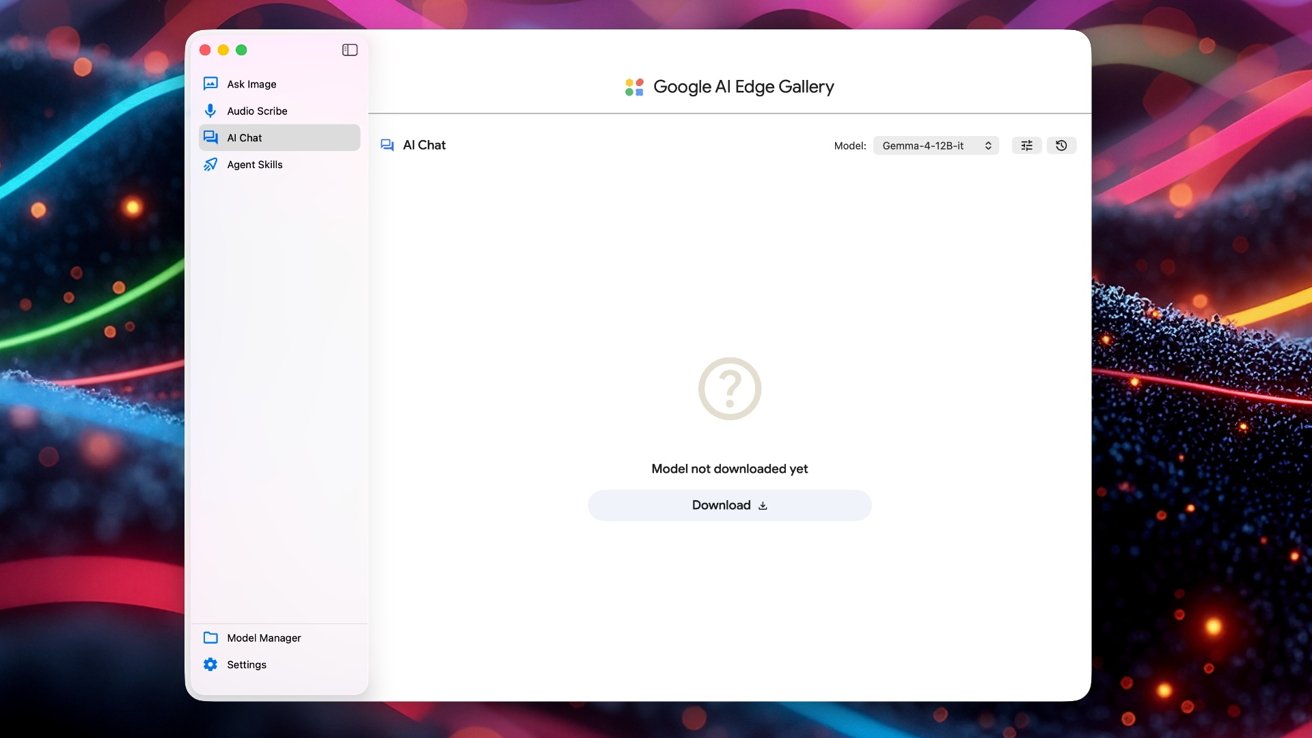
To make local multimodal AI easier to use, Google released the AI Edge Gallery app for macOS. This desktop tool lets you download, manage, and run Gemma models, including Gemma 4 12B, entirely on your Mac without an internet connection. Once installed, AI Edge Gallery works as a local control panel: you can select a model, choose a task such as chat, code generation, or image understanding, and send prompts directly to the model running on your laptop. AppleInsider notes that this is the first time Google’s own tool for Gemma has been made available on the Mac, even though enthusiasts have run Gemma locally through other frameworks before. Running models through AI Edge Gallery offers two main benefits: you can run AI offline when travelling or in secure environments, and your prompts and files stay on the device instead of passing through external servers.
How Gemma 4 12B Compares to Cloud Models and Larger Gemmas
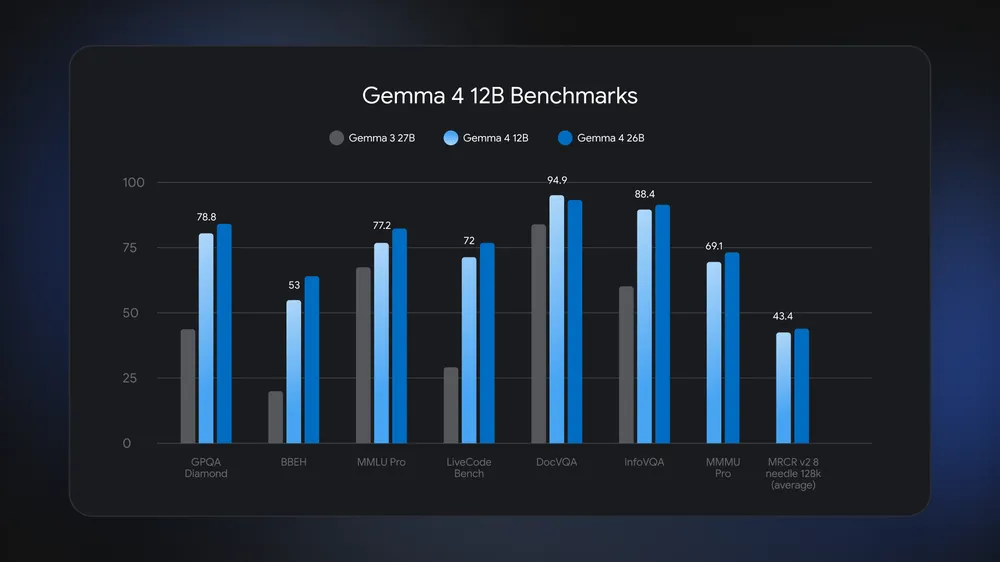
Cloud AI services still have advantages in raw scale, but Gemma 4 12B narrows the gap for many real workloads. Android Authority reports that this model performs close to the larger Gemma 4 26B Mixture of Experts model in benchmarks while remaining small enough to run on normal laptops with 16GB RAM. Technobezz adds that it beats the older Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA, highlighting gains in reasoning and document understanding. For typical users, this means that a local multimodal AI model can now handle code assistance, technical Q&A, and multimodal analysis without feeling far behind premium cloud systems. You still might rely on the cloud for very large context windows or heavy batch workloads, but Gemma 4 12B brings day‑to‑day queries, coding sessions, and media analysis onto your own hardware, cutting network latency from the loop.
Practical Use Cases and Privacy Benefits of Running AI Offline
Running the Gemma 4 12B model locally gives you more control over both performance and privacy. With no network in the loop, responses arrive without cloud round‑trips, and you avoid token‑based usage costs for many tasks. Google’s examples include a financial analyst summarising confidential quarterly reports stored on their laptop, or a field engineer using image analysis to inspect equipment and pull up local schematics. Because the model runs on-device, sensitive documents, screenshots, and voice recordings never leave your machine. Google’s AI Edge Eloquent reference app shows how this translates into everyday tools: it performs offline voice dictation and text editing, turning speech into text without sending audio to remote servers. For developers, this local, agent‑style workflow—combining speech, screenshots, code, and tool calls in one session—opens the door to building custom assistants that can run AI offline wherever a 16GB laptop can go.