What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is Google DeepMind’s new 12‑billion‑parameter multimodal AI model that runs locally on laptops with 16GB memory, offering near‑flagship performance while removing cloud dependence and dedicated encoders for images and audio to improve efficiency, privacy, and accessibility for everyday users and developers. Built as the missing middle of the Gemma 4 family, it sits between lightweight mobile models and heavier 26B and 31B options. The model is small enough to run on consumer hardware yet strong enough for multi‑step reasoning, agentic workflows, and multimodal AI tasks such as document visual question answering. Early developer reaction in local AI communities has been warm, with many seeing it as a turning point where local AI models become powerful enough for serious work instead of being limited to experiments or narrow use cases.
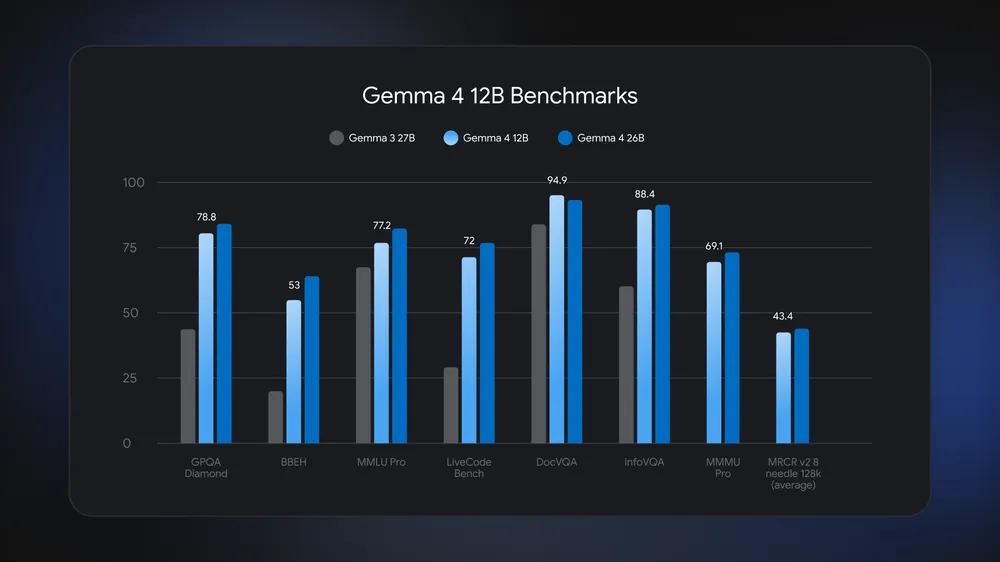
Near-26B Performance You Can Run on a Laptop
Gemma 4 12B’s main surprise is how close it comes to the larger Gemma 4 26B while using around half the memory. Benchmarks from Google show the 12B model running neck and neck with 26B, even edging ahead on DocVQA for document visual question answering, and beating the older Gemma 3 27B on tests such as GPQA Diamond, MMLU Pro, and DocVQA. Yet it is designed to run on a laptop with 16GB of system RAM or VRAM, which many users already have. According to Google DeepMind, the model “runs locally on any laptop with 16GB of system RAM or VRAM, using roughly half the memory of the larger Gemma 4 26B while staying close to it on benchmarks.” That performance-for-size tradeoff directly advances the goal to run AI on laptop hardware without data center support.

Unified Architecture and Native Audio for Multimodal AI
Most multimodal AI models bolt separate encoders onto a language model to handle images and audio, which adds latency and memory overhead. Gemma 4 12B takes a different route. It passes images and audio directly into the LLM backbone through a unified architecture, removing encoder dependencies and cutting computational cost. For vision, a compact 35‑million‑parameter embedding module slices images into 48×48 pixel patches and maps them into the hidden dimension with a single matrix multiplication, instead of running them through 27 transformer layers and about 550 million parameters. Audio goes even leaner: raw 16 kHz waveforms are split into 40‑millisecond frames and projected into the same space as text tokens, with no dedicated audio encoder. This native audio support on a mid-sized model enables richer multimodal AI workflows, from speech recognition and speaker diarization to video analysis and image understanding, in a single local AI model.

Local AI Models, Privacy, and Practical Agentic Workflows
By making a multimodal model that can run AI on laptop hardware, Gemma 4 12B reshapes what is practical outside data centers. Developers can run advanced reasoning and agentic workflows offline without sending data to cloud services, strengthening privacy for sensitive documents, images, or recordings. The model’s Multi‑Token Prediction drafters, enabled by default, use spare compute to speculate on upcoming tokens and speed up generation, which helps local sessions feel responsive. While some early community commentary suggests that other models may still lead on coding benchmarks, Gemma 4 12B targets broader everyday tasks where a balanced, efficient multimodal AI is more important than top coding scores. With weights released under the Apache 2.0 license on platforms like Hugging Face and Kaggle, the barrier to experimentation and deployment drops sharply, bringing powerful local AI models within reach of many more users and small teams.






