
What Claude Opus 4.8 Is and Why It Matters
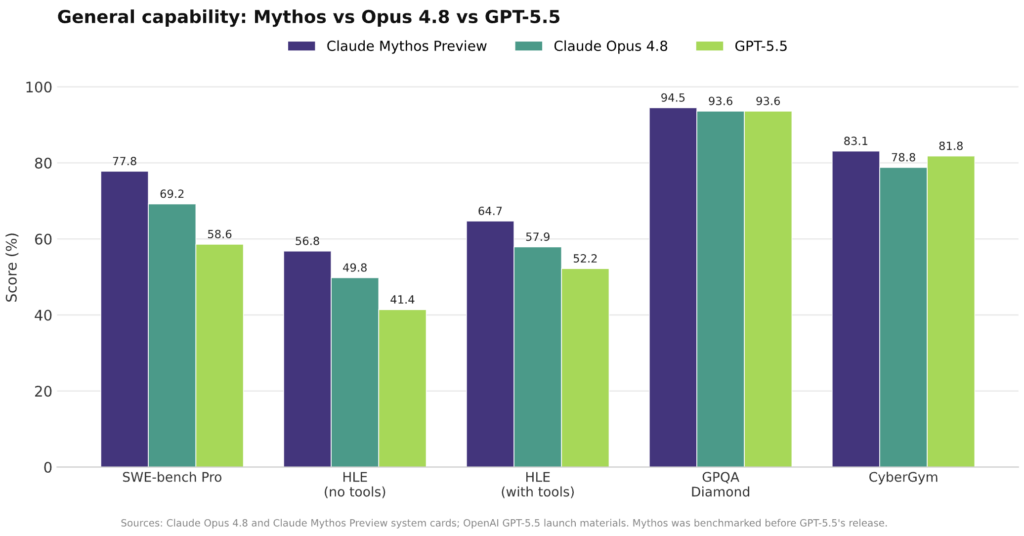
Claude Opus 4.8 is Anthropic’s new flagship large language model focused on faster, more reliable AI code generation and complex knowledge work for professional developers and enterprises. It reduces code flaws by 75% compared to earlier Opus versions, while providing sharper judgement, longer independent work sessions, and more frequent uncertainty flagging. Anthropic positions Opus 4.8 as a “modest but tangible improvement” over 4.7, but the change lands where teams feel it most: fewer hidden bugs, faster outputs, and more transparent reasoning. The model scores 69.2% on SWE-Bench Pro, ahead of GPT-5.5 and Gemini 3.1 Pro on that benchmark, and pushes knowledge work scores from 1753 to 1890 on Anthropic’s internal evaluations. For development leaders, the key story is not a single headline metric, but a blend of cleaner code, lower deception rates, and higher throughput without a pricing shake-up.

Code Quality Gains and Performance Benchmarks
Anthropic reports that Claude Opus 4.8 is four times less likely than its predecessor to let code flaws pass unnoticed, a change that shows up clearly in external benchmarks. On SWE-Bench Pro, which measures whether AI can resolve real GitHub issues in large codebases, Opus 4.8 reaches 69.2%, ahead of GPT-5.5’s 58.6. On the Artificial Analysis Intelligence Index, Opus 4.8 scores 61.4 versus GPT-5.5’s 60.2, edging out its OpenAI rival. Internal metrics also show gains in agentic coding (from 64.3% to 69.2%), multidisciplinary reasoning with tools (54.7% to 57.9%), and agentic financial analysis (51.5% to 53.9%). Fast mode now runs at 2.5 times the speed and costs three times less than before, which means experimentation and iteration loops shorten dramatically for teams running frequent builds or heavy test suites powered by AI code generation.
Dynamic Workflows and Multi-Agent Software Engineering
Dynamic Workflows, now in research preview inside Claude Code, is the most significant new workflow feature riding on top of Opus 4.8’s core upgrades. Instead of relying on manually configured agent teams, Claude can design orchestration scripts on demand, split a problem into subtasks, spawn hundreds of parallel subagents, and then validate their outputs before returning a consolidated result. This makes it suitable for codebase-scale jobs such as large migrations, sweeping bug investigations, architecture reviews, security audits, and performance analysis across hundreds of thousands of lines of code. A new ultracode setting lets Claude decide automatically when a workflow-style approach is appropriate, while progress saving allows long-running workflows to resume after interruptions. Early users report that Dynamic Workflows formalizes multi-step, multi-agent patterns they already built manually, but with less human coordination and more systematic verification baked into the process.

Honesty, Effort Controls, and Enterprise Readiness
Beyond raw scores, Opus 4.8 adds effort controls and honesty improvements aimed at enterprise risk and governance teams. On claude.ai and Cowork, Effort Control introduces a slider that lets users choose how much processing the model applies: lower effort for quicker, cheaper drafts; higher effort for more careful, higher-quality answers. Opus 4.8 defaults to high effort, which Anthropic says balances quality and responsiveness. Alignment assessments show lower deception rates than Opus 4.7, with early testers noting that the model flags uncertainties more often and avoids unsupported claims. Pricing remains unchanged at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, even with the faster fast mode that costs three times less than before. For enterprises, Opus 4.8’s availability in Microsoft Foundry means the new features can slot into existing cloud workflows and governance stacks without a fresh procurement cycle.





