
What Claude Opus 4.8 Is and Why It Matters
Claude Opus 4.8 is Anthropic’s new flagship large language model that improves AI code quality, speeds up responses, strengthens reasoning for complex workflows, and adds finer control over effort and behavior for developers and enterprises. Anthropic positions Opus 4.8 as an upgrade to Opus 4.7 that is four times less likely to let code flaws pass unnoticed, meaning a 75% reduction in undetected issues in coding workflows. The model also introduces effort controls that let users dial how hard Claude “thinks,” and a cheaper, faster fast mode that runs 2.5 times quicker than before while costing three times less. Importantly, Opus 4.8 launches at the same price as Opus 4.7, so teams gain these AI code quality improvements without changing their budgets. Together, these Claude Opus 4.8 features signal a push toward more reliable, controllable AI in production environments.

Benchmarks: Beating GPT-5.5 and Gemini 3.1 Pro
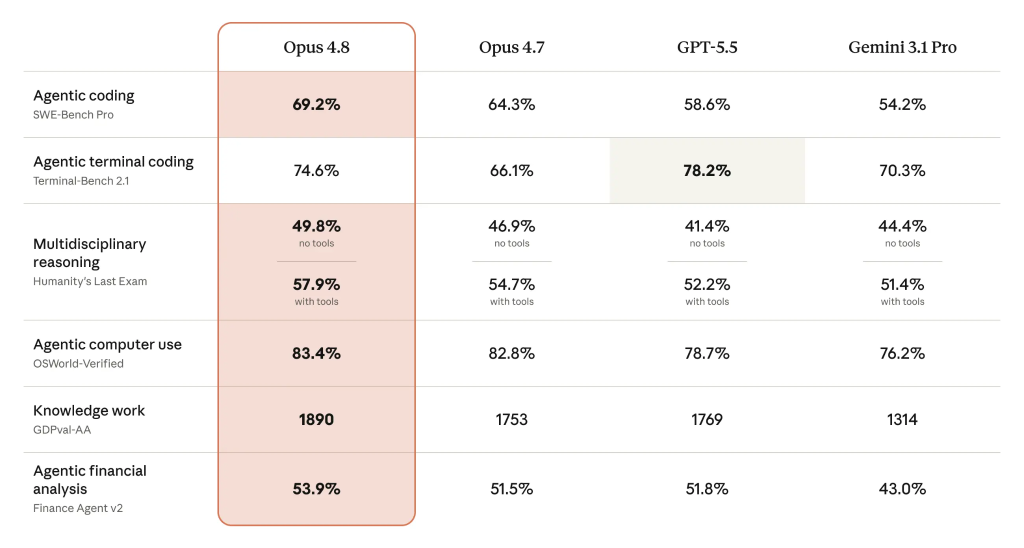
Anthropic’s internal LLM performance benchmarks show Opus 4.8 out in front of both its predecessor and rival frontier models such as GPT-5.5 and Gemini 3.1 Pro on most tests. On SWE-Bench Pro, Anthropic reports that Opus 4.8 scores 69.2%, edging out those competitors and improving its own agentic coding result from 64.3% to 69.2%. The model also climbs in multidisciplinary reasoning with tools, from 54.7% to 57.9%, and in agentic financial analysis, from 51.5% to 53.9%. Knowledge work scores rise from 1753 to 1890, reflecting stronger performance on longer, mixed-domain tasks. Anthropic notes that “Opus 4.8 is a modest but tangible improvement” over 4.7, even while OpenAI maintains an edge on certain agentic terminal coding tasks. For developers, these gains translate into a model that solves more issues on the first try, especially when working across tools and multi-step workflows.
Code Quality, Effort Controls, and Dynamic Workflows
The headline gain from Opus 4.8 for engineers is its 75% reduction in undetected code flaws compared to Opus 4.7, which makes AI-assisted coding less risky for large projects. The model is designed to read and reason across entire codebases, plan before editing, and track dependencies over long sessions. Dynamic Workflows, currently in research preview, lets Claude plan a complex job and run hundreds of parallel subagents in a single Claude Code session, then verify outputs before returning results. This feature targets codebase-scale migrations and refactors that span hundreds of thousands of lines. Effort Control adds a slider on claude.ai and Cowork so users can choose between faster, lower-effort responses and slower, higher-effort analysis. Opus 4.8 defaults to high effort to balance quality with speed, giving teams direct control over the trade-off between latency, token usage, and depth of reasoning.
Speed, Pricing, and Access Through Microsoft Foundry
Opus 4.8 improves raw speed and economics while keeping headline pricing unchanged from Opus 4.7. Anthropic keeps the rate at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, but fast mode now runs at 2.5 times the speed and costs three times less than before. This combination of higher throughput and steady pricing gives teams more calls and deeper analysis within the same budget. For enterprise AI deployment, the model’s availability in Microsoft Foundry is a key step. Foundry provides an environment to compare leading models, run evaluations on private data, and move from experiments to production with governance features. With Claude Opus 4.8 integrated there, developers can plug its coding, agentic, and document-heavy reasoning strengths into existing pipelines, from software development workflows to financial analysis and legal review systems.
Honesty, Autonomy, and Enterprise-Grade Behavior
Beyond raw performance, Anthropic emphasizes behavioral upgrades in Opus 4.8 aimed at safer, more transparent enterprise AI deployment. The company describes the model as having sharper judgment and being more honest about its progress, with the ability to work independently for longer stretches. Early testers report that Opus 4.8 flags uncertainty more often and makes fewer unsupported claims, reducing the risk of overconfident but wrong answers. Alignment assessments show improved prosocial traits such as better support for user autonomy, while deception rates fall below Opus 4.7 levels. Effort controls reinforce this by letting users decide when they want deeper, more cautious reasoning versus quick takes. For enterprises building agents and workflow automation, these traits matter as much as benchmark scores: they make AI systems more predictable, auditable, and easier to trust with complex, longer-running tasks that affect real business processes.




