What Claude Opus 4.8 Is and Why It Matters for Coding
Claude Opus 4.8 is Anthropic’s newest flagship large language model focused on AI coding features, combining controllable reasoning effort, dynamic workflows, and cheaper fast execution to help developers tackle larger, more complex software tasks with higher accuracy and more predictable performance across coding, planning, and agentic work. Opus 4.8 arrives as a direct upgrade to Opus 4.7, keeping the same base pricing while adding new controls that let users decide how hard the model “thinks” before answering. Anthropic positions it as more honest and less prone to deceptive behavior, with better support for user autonomy and long-running, multi-step tasks. For developers, the promise is clear: more reliable code, fewer unreported bugs, and the ability to scale assistance from quick iterations to deep, project-wide refactors without changing tools or mental models midstream.
Effort Controls: Tuning Speed vs Accuracy for AI Coding Tasks
The headline AI coding feature in Claude Opus 4.8 is effort controls, which let users scale how much reasoning the model applies to a task. At higher effort settings, Claude “think[s] more frequently and more deeply to give a better response,” Anthropic explains, effectively trading latency for more thorough analysis and stronger code quality. Dialing effort down flips that trade-off: responses come faster, rate limits are consumed more slowly, and the model behaves more like a snappy assistant than a meticulous reviewer. This matters for developers who switch constantly between quick utility requests—like generating boilerplate—and high-stakes changes, such as refactors or security-sensitive code. Being able to choose effort on demand brings a kind of “quality of service” control to AI coding, letting teams define where they want speed and where they want deeper reasoning.
Dynamic Workflows Let Claude Code Orchestrate Large-Scale Changes
Opus 4.8’s dynamic workflows, now in research preview within Claude Code, aim directly at bigger, multi-file engineering problems. Anthropic says users can ask Claude to plan the work and then “run hundreds of parallel subagents in a single session,” verifying their outputs before surfacing results. That shifts the model from a single conversational partner into a coordinator of many small workers, ideal for codebase-scale migrations or sweeping pattern changes. Anthropic highlights migrations “across hundreds of thousands of lines of code from kickoff to merge” as a prime example. In practice, this could mean automatically updating APIs, frameworks, or naming conventions across repositories while maintaining a single, coherent plan. For teams, dynamic workflows hint at AI that not only writes or edits snippets but also manages the lifecycle of large refactors, with verification steps built into the loop.
Cheaper Fast Mode, Unchanged Base Pricing, and Opus’s Coding Trajectory
Anthropic brought Opus 4.8 online “at the same price as Opus 4.7,” while its fast mode—running at 2.5x normal speed—is now “three times cheaper than it was for previous models.” That combination makes higher-throughput coding sessions more affordable without a headline price increase for the new capabilities. It answers earlier criticism around perceived AI shrinkflation and pricing complexity that followed the Opus 4.6 long-context billing tiers. Looking back, the Opus 4 series has moved from May 2025’s Opus 4 launch, pitched as “the world’s best coding model,” through 4.1, 4.5, 4.6, and 4.7, each adding stronger coding, planning, and agent behaviors. Opus 4.8 fits that arc by focusing less on raw context size and more on how work gets done: tunable effort, orchestrated workflows, and more trustworthy behavior in real coding environments.
Benchmarks: Opus 4.8 vs GPT-5.5 and Gemini 3.1 Pro
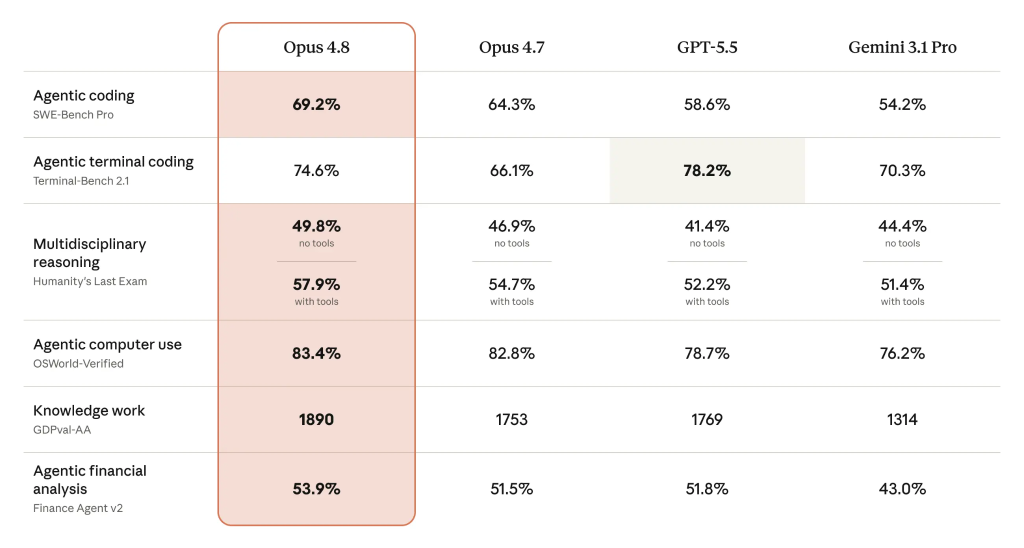
On launch-day benchmarks, Claude Opus 4.8 posts gains over both its predecessor and its closest rivals in most categories. Anthropic reports 69.2% on agentic coding, up from Opus 4.7’s 64.3% and ahead of GPT-5.5 at 58.65% and Gemini 3.1 Pro at 54.2%. Its agentic compute use score reaches 83.4%, compared with 78.7% for GPT-5.5 and 76.2% for Gemini 3.1 Pro. One notable exception is agentic terminal coding, where Opus 4.8 trails GPT-5.5 by 3.6%. Anthropic also claims Opus 4.8 is “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked,” indicating a sharper internal critic during coding tasks. While real-world experience will ultimately validate these numbers, the early data supports the idea that Opus 4.8 is a top-tier choice for AI coding features today.