
What Claude Opus 4.8 Is and Why It Matters for Developers
Claude Opus 4.8 is Anthropic’s newest flagship AI model, designed to improve coding, reasoning, and agentic workflows by adding effort controls, faster execution modes, and dynamic multi-agent capabilities while keeping the same pricing tier as its predecessor for individual and enterprise users. For developers, the release focuses on three areas: more control over how much “thinking” the model does, better support for large-scale coding tasks, and faster, cheaper fast mode responses. According to TestingCatalog, Opus 4.8 is available across the Claude website, API, and existing plans, with early users reporting stronger judgment and fewer unflagged errors in complex work. Anthropic’s Alignment team also reports that Opus 4.8 has lower rates of misaligned behavior and improved support for user autonomy, which should matter as teams experiment with more agentic, semi-automated coding pipelines.
Effort Controls: Tuning Speed vs. Depth for AI Coding Features
Effort controls are the headline usability feature in Claude Opus 4.8, allowing users to dial how much computation the model spends on a task. At higher effort settings, Claude “thinks more frequently and more deeply to give a better response,” Anthropic explains, which can be valuable for tricky code refactors, cross-service debugging, or legal and policy reviews. Lower effort trades some depth for faster outputs and slower rate-limit consumption, useful for quick code stubs, documentation, or exploratory questions. This control is available across claude.ai for all users, so teams can standardize profiles such as “low effort for exploratory chat, high effort for production-critical code reviews.” In practice, effort controls turn Claude Opus 4.8 into a more flexible coding assistant: the same model can act as a lightweight helper during ideation, then shift into a more thorough reviewer when it is time to commit changes.
Dynamic Workflows in Claude Code: Parallel Agents for Big Codebases
The new dynamic workflows feature in Claude Code targets a common pain point: scaling AI coding features from small snippets to entire codebases. In research preview for Enterprise, Team, and Max plans, dynamic workflows let Claude Opus 4.8 plan a multi-step job, spawn hundreds of parallel subagents in a single session, and then verify their outputs before presenting results. Anthropic highlights codebase-scale migrations as a prime example, claiming Claude Code can now handle changes “across hundreds of thousands of lines of code from kickoff to merge.” For developers, that means tasks like framework upgrades, API renames, or cross-repo cleanup can be expressed as high-level instructions while Claude coordinates the detailed edits. The verification pass is key: combined with the model’s stronger self-checks, it aims to cut down on silent failures that make large automated refactors risky in real-world engineering workflows.
Faster, Cheaper Fast Mode with Stronger Self-Checking
Opus 4.8 also reworks fast mode, which runs the model at 2.5x its normal speed for latency-sensitive tasks. According to TestingCatalog, “fast mode now delivers responses at 2.5 times the previous speed at a third of the former cost,” yet Anthropic states that Opus 4.8 is offered at the same price tier as Opus 4.7 overall. That combination opens new options for interactive coding, IDE integrations, and CI bots that need quick feedback on tests or static analysis. On the quality side, Anthropic’s Alignment team reports that Opus 4.8 is “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked,” pointing to more reliable self-review. Early partners echo this, noting improved judgment in agentic and legal applications, where undetected mistakes can have outsized consequences.
Benchmarks, Agentic Skills, and What Opus 4.8 Changes in Practice
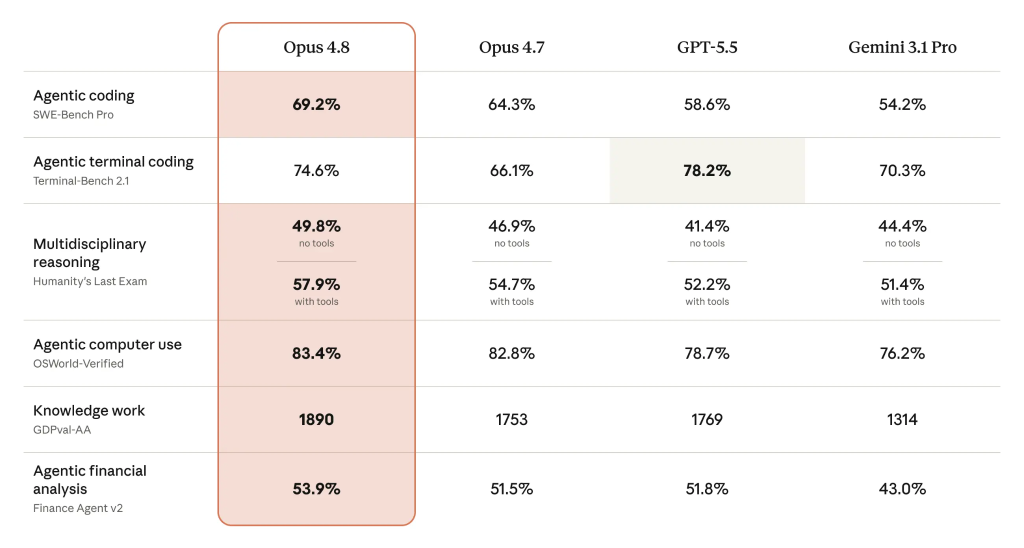
Benchmarks suggest Claude Opus 4.8 advances Anthropic’s push into agentic coding and multi-step workflows. The New Stack reports that Opus 4.8 reaches 69.2% on an agentic coding benchmark, up from Opus 4.7’s 64.3%, and ahead of GPT-5.5 at 58.65% and Gemini 3.1 Pro at 54.2%. Its agentic compute use score is 83.4%, beating GPT-5.5’s 78.7% and Gemini 3.1 Pro’s 76.2%, though GPT-5.5 still leads on agentic terminal coding by 3.6 percentage points. For developers, those numbers translate into a model that is better at planning, executing, and monitoring multi-step coding tasks such as test generation, environment setup, and progressive refactoring. Combined with effort controls and dynamic workflows, Claude Opus 4.8 positions Claude Code as a platform not just for code completion, but for orchestrating larger coding projects end to end.




