What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is a 12‑billion‑parameter, open multimodal AI model from Google that runs on standard 16GB laptops, bringing near‑cloud performance for text, image, and audio tasks directly to local machines. Unlike many local AI models, Gemma 4 12B is designed to nearly match the benchmark performance of larger 26B models while using roughly half the memory, so creators and developers can run AI locally without a data center GPU. It supports laptop AI processing for multistep reasoning, document question answering, and agent‑style workflows that used to require heavier hardware or cloud APIs. Because the model weights ship under an Apache 2.0 license, you can fine‑tune, embed, or redistribute Gemma 4 12B inside your own tools while keeping sensitive data offline. In short, it turns a mid‑range laptop into a practical multimodal AI workstation.

How Gemma 4 12B Runs on a 16GB Laptop
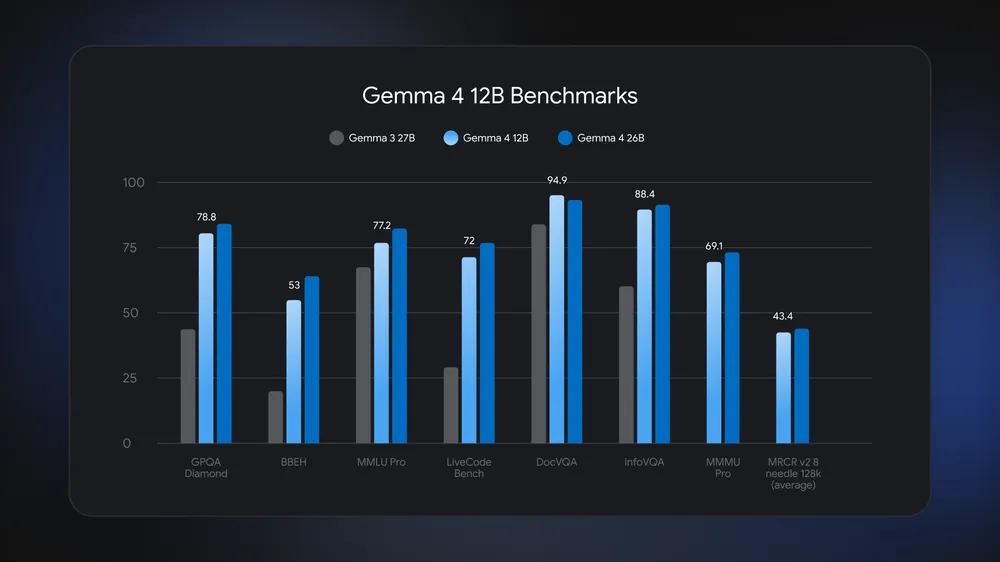
Gemma 4 12B is sized so that a consumer laptop with 16GB of system RAM or VRAM can load and run it, using far less memory than typical 20B+ local AI models. According to Google DeepMind, “Gemma 4 12B runs locally on any laptop with 16GB of system RAM or VRAM,” sitting at just under 18GB of weights on Hugging Face and Kaggle. It nearly matches Gemma 4 26B benchmarks and even beats the older Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA, making it a strong general model for laptop AI processing. Performance gains also come from built‑in Multi‑Token Prediction drafters, which use spare compute to predict multiple future tokens and speed up generation. In practice, that means faster responses without needing external accelerators, as long as you manage background apps and keep enough memory free.

Native Audio and Multimodal AI on Your Desk
Where Gemma 4 12B stands out among local AI models is its unified architecture for multimodal AI: it accepts text, images, and audio without separate encoders. For vision, a slim 35‑million‑parameter embedding module splits images into 48×48 patches and projects them directly into the model’s hidden dimension, replacing heavier vision transformers from other Gemma variants. Audio goes even leaner; the model slices raw 16 kHz audio into 40‑millisecond frames and projects them into the same space as text tokens, enabling native audio support on a mid‑sized model for the first time in the Gemma line. This design cuts latency and memory use for laptop AI processing while supporting multimodal AI use cases such as speech recognition, speaker diarization, image understanding, and video analysis. For users, that means voice‑driven prompts, narrated summaries, and frame‑by‑frame video commentary, all running offline.

Practical Setups: Running Gemma 4 12B Locally
To run Gemma 4 12B locally, you download the Apache 2.0‑licensed weights (about 18GB) from platforms like Hugging Face or Kaggle, then load them through your preferred runtime. On desktops or gaming laptops, you can use GPU‑oriented tools such as text‑generation‑webui, vLLM, or other local AI model launchers; on ultrabooks, CPU‑friendly runtimes and quantized variants help fit within 16GB. Close memory‑hungry apps and disable heavy browser sessions to keep enough headroom for laptop AI processing. Once running, you can connect Gemma 4 12B to note‑taking tools, IDE extensions, or command‑line agents to run AI locally without cloud calls. Many users in local LLM communities see it as “one of the most exciting models” for non‑coding tasks, while acknowledging that other models like Qwen may still outperform it on intensive coding benchmarks.
Real‑World Use Cases for Creators and Developers
Gemma 4 12B is suited to creators and developers who want multimodal AI without sending data to the cloud. Writers can run AI locally to draft articles, summarize research, or build document Q&A tools that rely on Gemma 4 12B’s strong DocVQA performance. Audio creators can record raw speech and let the model handle transcription, speaker labeling, and meeting summaries, while video creators can feed frames and narration to generate captions or highlight reels. Developers can prototype agentic workflows that combine text reasoning with audio and image understanding, although heavy coding tasks may be better served by specialized code models. The open license makes it safe to embed in internal tools, add fine‑tuned behaviors, or integrate with local search indices. For many workflows, Gemma 4 12B turns a 16GB laptop into a private, always‑available multimodal AI stack.





