What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is a 12‑billion‑parameter multimodal AI model from Google DeepMind that delivers near‑flagship language, vision, and audio performance while running locally on consumer laptops with 16GB of memory, narrowing the gap between cloud-scale systems and everyday personal devices for tasks such as reasoning, document understanding, and media analysis. Unlike many large models that demand powerful GPUs or data center infrastructure, Gemma 4 12B is sized for ordinary hardware without giving up much quality versus larger relatives. Google positions it between its lighter mobile Gemma versions and the heavier 26B and 31B models, which previously handled most advanced desktop workloads. By pairing laptop AI processing with support for text, images, and audio in one unified architecture, Gemma 4 12B pushes local AI models closer to what many users expect from cloud assistants, but without constant connectivity.

Laptop-Friendly Power: Near 26B Performance on 16GB Machines
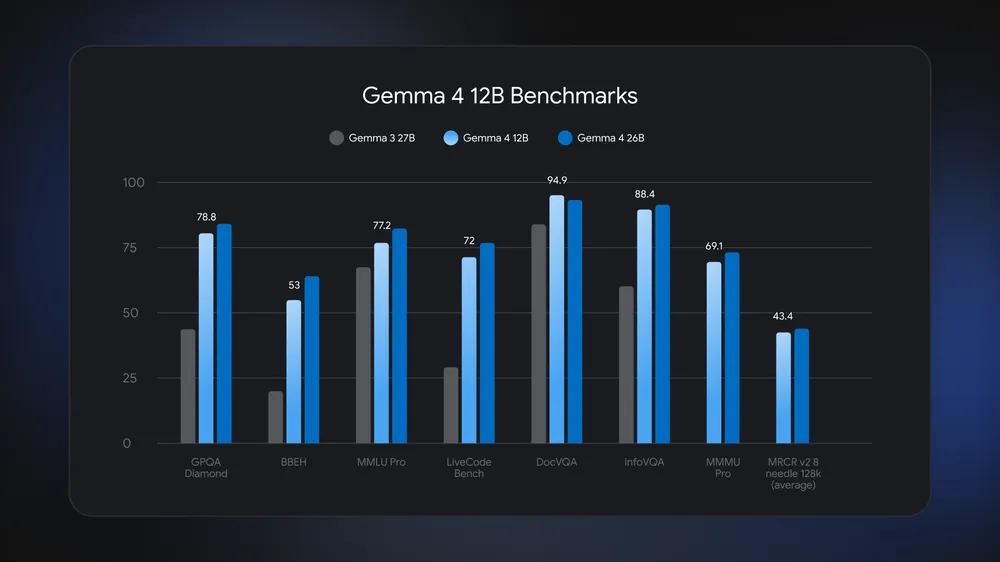
The defining feature of the Gemma 4 12B laptop story is efficient AI performance: Google says the model “runs locally on any laptop with 16GB of system RAM or VRAM,” yet stays close to the Gemma 4 26B Mixture of Experts on benchmarks. That means users can run multi‑step reasoning, complex document question answering, or agentic workflows without specialized accelerators. Benchmarks shared by Google show Gemma 4 12B roughly neck and neck with the 26B model, even edging past it on DocVQA, a key test for document visual question answering. It also clearly exceeds the older Gemma 3 27B on demanding evaluations like GPQA Diamond, MMLU Pro, and DocVQA. For many people, this middle tier is the sweet spot: far more capability than mobile‑class models, but no need for data center‑grade hardware or cloud credits to unlock advanced features.

Unified Multimodal Design: Text, Images, and Audio Offline
Gemma 4 12B is more than a small model; it is a new take on multimodal AI offline. Earlier Gemma versions and many other local AI models rely on separate encoders for images and audio, which add latency and inflate memory use. Gemma 4 12B drops those heavy components and feeds non‑text data straight into the language model backbone. A slim 35‑million‑parameter embedding module breaks images into 48×48 pixel patches and projects them into the model’s hidden space with a single matrix multiplication instead of 27 vision transformer layers. Audio goes even leaner: raw 16 kHz waveforms are cut into 40‑millisecond frames and projected into the same dimensional space as text tokens. This unified setup enables laptop AI processing for speech recognition, speaker diarization, image understanding, code generation, and even video analysis, all within a single, laptop‑sized model.

Privacy, Latency, and the Trade-Offs of Local AI Models
Running a multimodal AI model like Gemma 4 12B locally changes more than hardware requirements; it shifts expectations around privacy and responsiveness. With multimodal AI offline, voice notes, documents, and screenshots can be processed without leaving the device, shrinking the attack surface compared with cloud‑only workflows. Latency also improves when requests no longer depend on network speed or server queues. Early community reactions on forums such as r/LocalLLaMA reflect strong interest in its native audio support and unified architecture, although some developers warn that coding performance may lag behind specialized local models such as Qwen 3.6 35B or Nvidia Nemotron 3 Nano 30B‑A3B. For non‑coding uses—summaries, assistants, media understanding—the Gemma family is seen as stronger. The 12B model crystallizes a trade‑off many users will accept: slightly weaker niche skills in exchange for private, near‑26B‑level general performance on a standard laptop.
Opening Advanced AI to Mainstream Laptops
Gemma 4 12B lands at a time when memory costs are under pressure, yet demand for personal AI is rising. Research summarized by Northeastern University reports that memory prices “jumped roughly 90% in the first quarter of 2026 against the previous quarter,” as chip makers shifted production toward data center‑scale parts. In that context, an 18GB‑weight model that can run on 16GB machines matters: it sidesteps some of the economic and hardware barriers that have limited advanced AI to enthusiasts and enterprises. Because the weights are released under an Apache 2.0 license and available on Hugging Face and Kaggle, developers and tinkerers can integrate Gemma 4 12B into desktop apps, note‑taking tools, or local agents without licensing friction. The result is a practical step toward everyday laptops running capable, multimodal AI assistants without constant cloud dependence.