From Raw Data to AI-Ready Pipelines
Enterprise data platforms for AI are integrated data preparation and delivery systems that convert fragmented, unstructured, and governed enterprise information into AI-ready data pipelines that can feed training, inference, and agentic workloads without rebuilding existing infrastructure. For many organizations, the main blocker to AI at scale is not models or GPUs, but the gap between messy operational data and query-ready datasets. Traditional enterprise data preparation relies on manual ingestion, complex ETL pipelines, and repeated copying of data into new silos, creating delays and compliance risk. Modern platforms tackle this gap by tying governance, classification, and performance into a single data layer. Instead of moving petabytes between systems, they expose a structured view of query-ready unstructured data directly to AI platforms, cutting time-to-deployment and removing the data bottleneck that stalls funded AI initiatives.
GPU-Accelerated Data Infrastructure Shrinks Preparation Windows
Everpure’s Data Stream shows how GPU-accelerated data infrastructure is reshaping enterprise data preparation for AI. Built on the NVIDIA AI Data Platform reference design, Data Stream runs a GPU-accelerated pipeline that spans ingestion through inference, replacing slow, manual preparation with high-throughput processing. According to Everpure, Data Stream reduces data preparation timelines from months to minutes while keeping data within enterprise boundaries through stream-level access controls. The platform is part of a broader AI-ready data infrastructure strategy anchored by Everpure Data Intelligence, which discovers, classifies, and contextualizes data across SaaS, cloud, on-premises, and mainframe environments. That intelligence layer creates a metadata-rich relationship graph exposed via APIs and the Model Context Protocol, so AI agents can access governed context without copying raw files. The result is a tighter connection between secure enterprise data and accelerated compute, closing the gap between experimentation and production AI services.

AI-Ready Data Lakes Remove Bottlenecks in Demanding Sectors
In sectors like advertising technology, data infrastructure itself has become the main bottleneck to AI-ready data pipelines. Eon’s AI-Ready Data Lake Infrastructure is gaining traction among AdTech platforms that process hundreds of billions of daily events across bidding, attribution, audiences, and reporting. Many of these organizations carry layers of ingestion frameworks, transformation jobs, and monitoring tools devoted entirely to enterprise data preparation. Eon takes a different path: it automatically turns operational data into an open, Apache Iceberg-based data lake as it lands, continuously optimizing storage, validating quality, and maintaining metadata for analytics and AI agents. CEO Ofir Ehrlich notes that every enterprise “has the same problem in a different costume” because AI projects are funded while data remains inaccessible. By standardizing data as it arrives, Eon provides a reusable, governed foundation that supports both real-time analytics and future AI workloads without new pipeline sprawl.

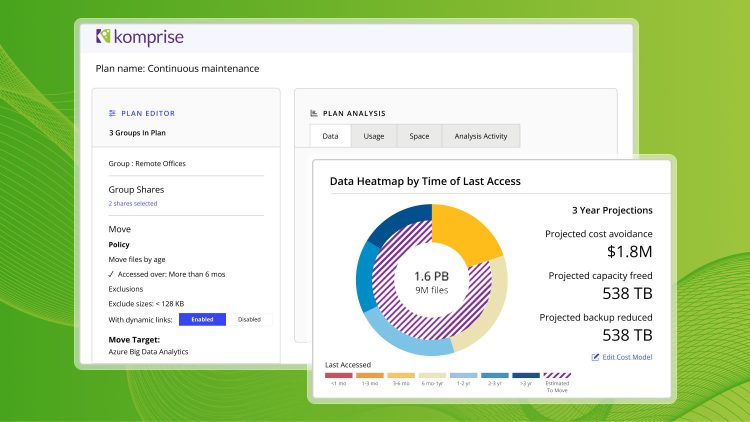
Query-Ready Unstructured Data Without Moving Files
Unstructured data dominates enterprise storage but remains largely unused in AI because it lacks schema, quality, and affordable access paths. Komprise targets this gap with Transparent File Tables (TFT), which present a structured, tabular view of unstructured files to platforms like Snowflake and Databricks. TFT relies on Komprise’s distributed, scale-out architecture to globally classify unstructured data and expose enriched metadata plus a pointer to the underlying files. The pointers use Komprise Transparent Move Technology so AI and analytics platforms can access remote data without moving a single file, dynamically loading content only when needed. IDC estimates that unstructured data represents more than 80% of the enterprise footprint, yet less than 1% is used in AI, underscoring the wasted potential. By turning this dark data into query-ready unstructured data, Komprise allows AI pipelines to join files with existing tables, enabling new dashboards and agents without massive data migration.

Integrated, Governed Platforms Remove the Need to Rebuild
Across these offerings, a clear pattern is emerging: enterprises can now deploy AI-ready data pipelines without rearchitecting core storage or shuttling data between systems. Everpure ties GPU-accelerated pipelines to a governance-rich metadata layer, while Eon converts incoming operational streams into an open data lake designed for analytics and AI. Komprise exposes transparent, query-ready views of unstructured data to existing lakehouse platforms without copying files. These data bottleneck solutions share several traits: they preserve security and compliance, support scale-out architectures, and present query-ready data where AI teams already work. Strategic alignments, such as Everpure’s integration with the NVIDIA AI Data Platform and Komprise’s support for Snowflake and Databricks, show that data infrastructure vendors and platform leaders are converging on integrated stacks. Together, they remove the last-mile friction between raw enterprise data and AI-ready datasets, turning data infrastructure readiness into a competitive advantage rather than a constraint.






