A Strategic Play to Escape the Squeeze in AI Coding Assistants
Cursor’s release of Composer 2.5 marks a strategic attempt to regain ground in the AI coding assistant market, where Claude Code and other agents have seized mindshare and revenue. Once seen as the default choice for AI-assisted coding, Cursor now faces intense pressure from rivals that can undercut it on pricing while also selling it underlying model access. By building on Moonshot’s Kimi K2.5 base rather than swapping to an entirely new model family, Cursor is betting that smarter post-training, not just bigger models, can close the gap. The company claims Composer 2.5 improves intelligence, reliability on long-running tasks, and overall usability, especially for developers who depend on multi-file edits and complex refactors. With millions of daily accepted lines of code and a large enterprise footprint already in place, this release aims less to prove viability and more to reassert leadership against premium tools such as Claude.
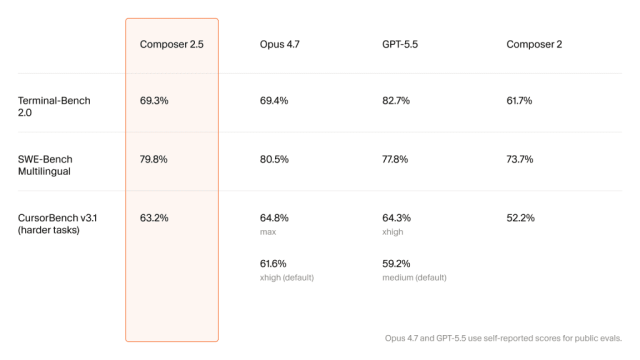
Benchmark Parity with Claude Opus 4.7 at Lower Cost
On headline benchmarks, Composer 2.5 now stands shoulder to shoulder with top-tier models. It scores 79.8% on SWE-Bench Multilingual, narrowly trailing Claude Opus 4.7’s 80.5% and edging out GPT-5.5’s 77.8%. On Terminal-Bench 2.0, it effectively matches Opus 4.7 (69.3% versus 69.4%), while GPT-5.5 leads at 82.7%. Cursor’s own harder-task suite, CursorBench v3.1, paints a more nuanced picture: Composer 2.5 reaches 63.2%, close to Opus 4.7’s max setting at 64.8%, and ahead of its default configuration as well as GPT-5.5’s default. Crucially, Cursor ties these results to cost efficient coding. At USD 0.50 (approx. RM2.35) per million input tokens and USD 2.50 (approx. RM11.75) per million output tokens for the standard tier, internal charts show Composer 2.5 reaching similar accuracy while competitors cost several dollars more per task, positioning it as a serious Claude alternative.

Up to 10x Cost Efficiency Opens AI Coding to More Teams
Composer 2.5’s most disruptive feature may not be raw intelligence but economics. Cursor reports up to 10x cost efficiency improvements over previous configurations and comparable frontier models, driven by its in-house tuning stack. Standard pricing undercuts many premium agents, while a faster variant—set as the default—comes in at USD 3.00 (approx. RM14.10) per million input tokens and USD 15.00 (approx. RM70.50) per million output tokens for teams willing to pay for speed. This pricing structure turns advanced AI coding assistance from a luxury add-on into something that can be deployed broadly across engineering teams, side projects, and smaller startups. For enterprises already watching token usage closely, more predictable and lower per-task costs make large-scale rollout less risky. In practical terms, Composer 2.5 pushes frontier-level coding performance into a price band where many developers can finally afford to run it as a default assistant, not an occasional tool.
Targeted Reinforcement Learning and Synthetic Tasks Drive Gains
Under the hood, Composer 2.5 demonstrates how far post-training can push a stable base model. Cursor says 85% of the total compute behind the model went into its own training and reinforcement learning on top of Kimi K2.5. The standout technique is targeted reinforcement learning with localized textual feedback: instead of a single success or failure signal at the end of a long trajectory, the model receives detailed hints at the exact point where it made a wrong tool call or planning error. That corrected path becomes a teacher signal, improving credit assignment. Composer 2.5 also trained on 25 times more synthetic tasks than its predecessor, exposing it to a much wider variety of real-world-like workloads before meeting users. Additional behavioral calibration refines communication style and coding consistency, helping the model follow nuanced instructions more reliably—key for enterprise teams that care about code standards as much as raw accuracy.
Longer, More Complex Coding Jobs and the Road Ahead
For developers, the practical test of any AI coding assistant is how it behaves inside a messy, real repository. Cursor positions Composer 2.5 as better at long-running jobs, repeated tool calls, and multi-file edits, specifically the kind of sustained coding sessions that often expose weaknesses in planning or state tracking. Internal and early user feedback suggests improvements in how the model maintains context across large refactors and complex instruction chains, though independent verification will come from live use on multi-file refactors and debugging sessions. Composer 2.5 is already available to all Cursor users, making head-to-head comparisons with Claude and other agents straightforward. Meanwhile, Cursor and its partners are training a larger model with significantly more compute, hinting at a future in which Composer 2.5 becomes the cost-efficient workhorse and a bigger sibling targets the highest-end enterprise and autonomous agent workloads.