
What Claude Opus 4.8 Is and Why It Matters for Production Code
Claude Opus 4.8 is Anthropic’s new flagship AI model focused on code quality improvement, faster iteration, and more honest autonomous behavior for developers building production systems. It aims to reduce hidden bugs in generated code, speed up end-to-end workflows, and give teams more control over how much effort the model spends on each task. Anthropic positions Opus 4.8 as an upgrade over Opus 4.7 across coding, reasoning, and long-running agentic work, without changing the base price. The model is also tuned to better support user autonomy and to cooperate less with misuse, which is important when you embed it deeply in CI pipelines or internal tools. For engineering leaders, Opus 4.8 is less about brand-new capabilities and more about making existing Claude-based workflows safer, faster, and more predictable at scale.
Code Flaw Reduction: What “Four Times Less Likely” Means in Practice
Anthropic reports that Claude Opus 4.8 is “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.” In practice, that translates to roughly a 75% reduction in unflagged code issues compared with Opus 4.7. For teams, this shifts Claude from being a prolific code generator to a more dependable reviewer that spots its own mistakes more often, reducing the time developers spend debugging AI-written patches. Early testers cited by Anthropic say Opus 4.8 has “sharper judgement, more honesty about its progress, and the ability to work independently for longer than its predecessors.” It also flags uncertainty more frequently and avoids unsupported claims, which matters when you wire it into agentic workflows that touch real repositories or infrastructure. The net effect is not bug-free code, but a model that fails more transparently and catches more of its own flaws before they hit production.

Speed, Effort Controls, and Developer Performance Gains
Opus 4.8 brings a 2.5x speed improvement in fast mode, and Anthropic says that mode is now three times cheaper than before. This lets teams run more iterations per hour for tasks like refactors, test generation, or multi-file edits, making tight feedback loops easier during active sprints. Effort Control adds a slider in claude.ai and Cowork so users can dial up deep reasoning or prioritize fast, lightweight answers that burn rate limits more slowly. Opus 4.8 defaults to high effort, which Anthropic describes as the best balance between quality and latency. For developer performance gains, this flexibility matters: you can keep high effort for risky changes (security-sensitive code, complex concurrency) and switch to lower effort for exploratory questions or documentation updates. Combined with lower fast-mode costs, it encourages teams to use the model throughout the development lifecycle instead of reserving it for occasional heavyweight tasks.
Dynamic Workflows and Scaling to Codebase-Level Changes
Dynamic Workflows, now in research preview, is the most developer-facing structural change in how Claude Opus 4.8 can be used. Within Claude Code, the model can “plan the work and then run hundreds of parallel subagents in a single session,” verifying outputs before returning them. Anthropic highlights codebase-scale migrations as a key use case: Opus 4.8 can manage transformations “across hundreds of thousands of lines of code from kickoff to merge.” This design moves beyond single-prompt coding toward orchestrated, multi-step automation that looks closer to a junior engineering team than a lone assistant. For production environments, the appeal is clear: you can offload large, repetitive changes while keeping a human in the loop for review and final merges. The feature currently targets Enterprise, Team, and Max plans, signaling that Anthropic sees it as an enterprise-grade workflow tool rather than a casual coding helper.
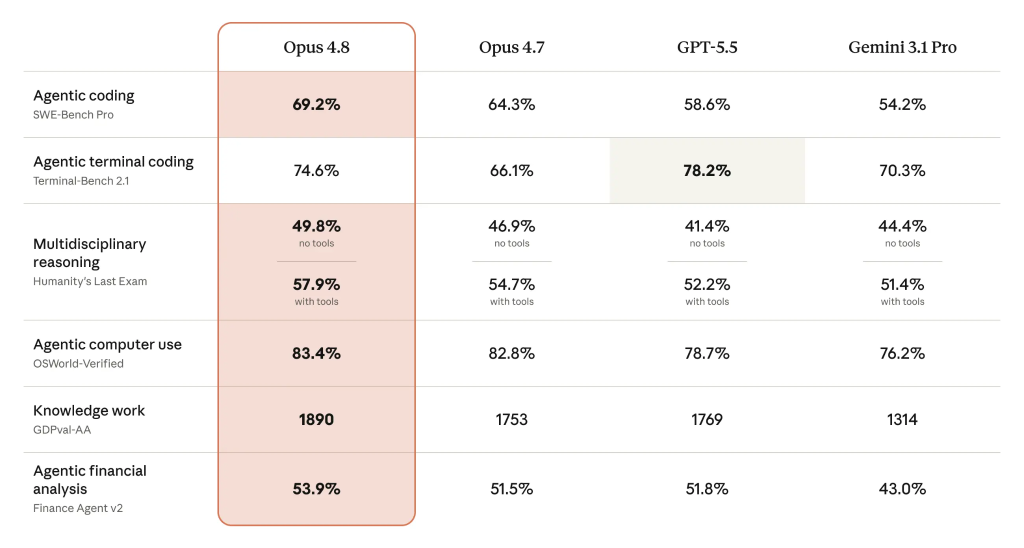
Benchmarks, Pricing Stability, and Competitive Positioning
On AI model benchmarks, Claude Opus 4.8 outperforms both GPT-5.5 and Gemini 3.1 Pro on many measures relevant to developers. Anthropic cites a 69.2% score on SWE-Bench Pro, ahead of GPT-5.5 and Gemini 3.1 Pro, and improvements over Opus 4.7 in agentic coding (from 64.3% to 69.2%), multidisciplinary reasoning with tools (54.7% to 57.9%), and agentic financial analysis (51.5% to 53.9%). Knowledge work scores rise from 1753 to 1890. The main area where Opus 4.8 trails is agentic terminal coding, where GPT-5.5 still leads by 3.6 percentage points. Despite these upgrades, Anthropic keeps pricing flat at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens. For teams comparing providers, Opus 4.8 offers improved code quality and speed without a pricing penalty, making it an attractive option for production-grade coding agents.




