Why LLM Inference Optimization Starts with Wasted Work
LLM inference optimization is the practice of reducing redundant computation, padding overhead, and memory waste so large language models answer queries faster and at lower GPU cost without changing their outputs. Most enterprise stacks today quietly burn GPU cycles on pretend work. Standard batching pads every sequence to match the longest input, so a single 2,000‑token document can force seven shorter ones into the same shape. The GPU obediently multiplies zeros by zeros, inflating compute time and VRAM usage with no gain in accuracy. At the same time, each new query causes the model to reread the same context from scratch, even when it has already processed that document minutes ago. These two inefficiencies—padding and redundant context recomputation—dominate many AI cost profiles, but they can be attacked with hardware‑aware sequence packing and memory engines designed for context caching.
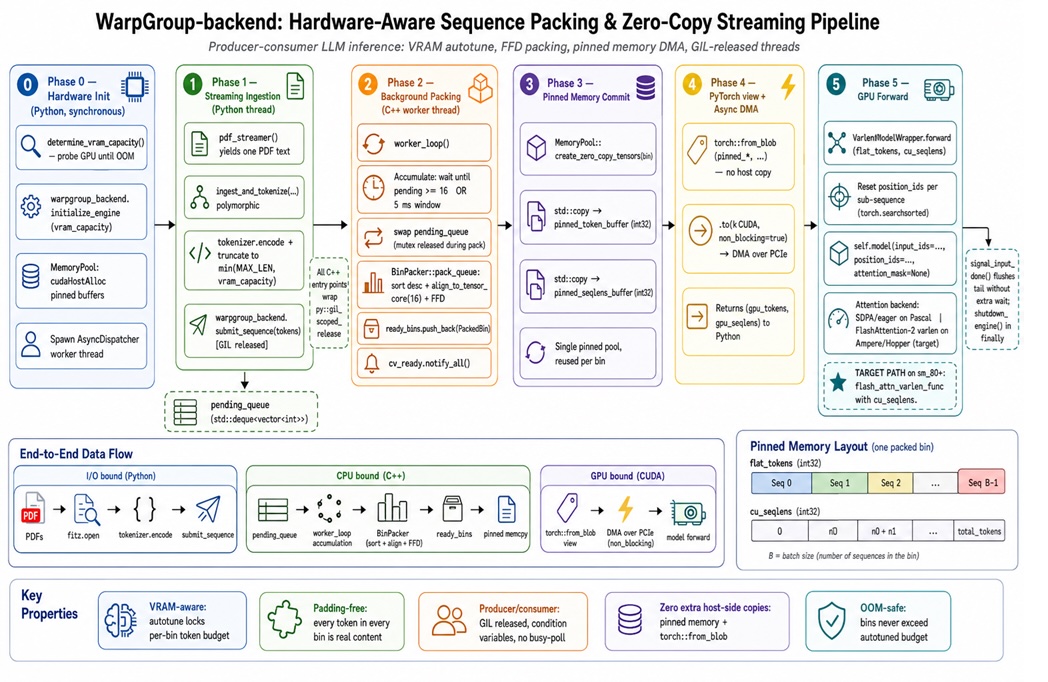
Hardware-Aware Sequence Packing: Stop Paying for Padding
Sequence packing replaces rectangular padding with a tightly packed "token ribbon" that keeps GPUs busy on real data instead of zeros. Instead of padding eight sequences to the longest length, a C++ backend such as WarpGroup arranges variable-length inputs into bins based on total tokens, like a careful bin-packing algorithm. Long sequences go in first and shorter ones fill the gaps, keeping each bin within a VRAM-measured token budget. To match GPU tensor core preferences, the backend rounds sequence lengths to friendly tile sizes, for example aligning to multiples of 16 tokens, which improves memory access and throughput. WarpGroup’s author reports up to 2.08× throughput gains on an H100 and up to 5.89× on a GTX 1080 by combining VRAM-aware bin sizing, pinned-memory transfers, and background C++ packing that avoids Python’s GIL. This approach targets padding overhead as a direct form of AI cost reduction.

Memory Engines and Context Caching: Stop Rereading the Same Document
While sequence packing fixes padding, it does not address the repeated cost of reprocessing the same context across queries. Memory engines such as Corbenic AI’s Taliesin introduce context caching: they save the internal memory state of a model after it reads a document and restore that state later, byte-identical, on demand. Instead of rereading a 100‑page report ten times, the model reads it once and reuses its stored memory for subsequent questions. According to Corbenic AI, “On a $0.69-per-hour graphics card, the longest test contexts took a model more than two minutes to process from scratch. Taliesin restored them in under seven seconds: a 21-times speedup, with no loss of accuracy.” Taliesin also showed identical outputs when moving AI memory between an Ampere A6000 and an Ada Lovelace RTX 4090, backed by SHA-256 hashes for cryptographic verification.

How the Two Approaches Compare and Work Together
Hardware-aware sequence packing and memory engines attack different parts of the LLM inference pipeline but share the same goal of GPU memory efficiency and AI cost reduction. Packing makes each forward pass cheaper by eliminating padding and aligning workloads to the GPU’s preferred shapes; memory engines make repeated queries cheaper by avoiding redundant context recomputation through context caching. In practical enterprise deployments, these techniques can be combined. Sequence packing keeps throughput high for new or mixed-length requests flowing through the system, while a memory engine preserves costly long-context states across sessions or servers, even when moving between GPU generations. Together, they shrink both per-request and recurring costs without changing model weights or accuracy. For teams already invested in LLM inference optimization, the message is clear: stop wasting compute on zeros and stop rereading the same documents when a better memory can handle the work.





