
Two Competing Visions for AI Security Testing
AI code agents are quickly reshaping how security teams approach code vulnerability detection and automated security scanning. Google’s CodeMender and Anthropic’s Mythos sit at the center of this shift, but they embody very different strategies. CodeMender is Google DeepMind’s AI security agent focused on finding software vulnerabilities, tracing root causes, and drafting patches that must pass human review before they ship. It is explicitly positioned as an internal-strengthening tool, aimed at helping security teams “secure the world’s code bases” rather than as a public coding assistant. Anthropic’s Mythos, by contrast, has been tested on critical infrastructure code as part of Project Glasswing, where it acts more like a highly autonomous security researcher. Both tools signal a move beyond simple static analysis into reasoning-driven AI security testing, yet they diverge sharply in access controls, workflow design, and how deeply they are trusted to operate without constant human direction.

Inside CodeMender: Controlled Power and Human-Gated Patching
CodeMender combines Google’s Gemini Deep Think models with program-analysis tooling to surface bugs and propose concrete fixes. Its workflow is built around a strict human-in-the-loop philosophy: the agent scans code, localises vulnerabilities, drafts candidate patches, and then hands every change to human reviewers for approval and deployment. Google is expanding access via an API, but only to vetted security experts rather than general developers, keeping the tool behind a controlled gate even as testing scales up. This cautious rollout reflects concerns that an AI capable of rapidly identifying and repairing flaws could be repurposed by attackers. For defenders, the benefit is a focused AI security testing companion that slots into existing code review and secure development lifecycles, amplifying expert teams instead of replacing them. The trade-off is that CodeMender’s impact still depends heavily on the throughput and judgement of human reviewers.
Inside Mythos: Exploit Chains and Self‑Verified Proofs
Mythos, evaluated under Project Glasswing, behaves less like an automated scanner and more like a senior security researcher. When used against dozens of production repositories, it didn’t just flag isolated issues; it constructed exploit chains, combining multiple low-severity bugs into a single, more dangerous attack path. Mythos can also generate working proofs of concept for suspected flaws. It writes exploit code, compiles it in a scratch environment, runs it, and iterates based on the outcome—closing the gap between speculative bug reports and demonstrated exploitability. This loop is particularly powerful for code vulnerability detection in complex systems where context and chaining matter. Compared with prior general-purpose models, Mythos showed a step-change in its ability to stitch together primitives and answer the critical question: “Can this actually be exploited?” That strength makes it a potent, but inherently sensitive, tool for automated security scanning in high-stakes environments.
Strengths, Weaknesses, and the Signal‑to‑Noise Problem
Both AI code agents excel at surfacing issues humans might overlook, but their weaknesses differ. CodeMender’s main limitation stems from its guarded availability and enforced human review: it scales only as fast as expert teams can triage and approve patches. That constraint may be intentional, but it caps automation. Mythos, meanwhile, faces challenges around consistency and noise. In Cloudflare’s tests, the model occasionally refused legitimate security research tasks, then accepted similar requests when phrased differently or run at another time. This probabilistic behaviour complicates repeatable workflows. Additionally, like other advanced scanners, Mythos can amplify the signal-to-noise problem: it finds many potential defects, leaving teams to decide which are real, exploitable, and urgent. Post-validation stages remain essential to filter false positives and rank risk. In practice, the most effective use of Mythos is alongside robust triage pipelines rather than as a fully autonomous decision-maker.
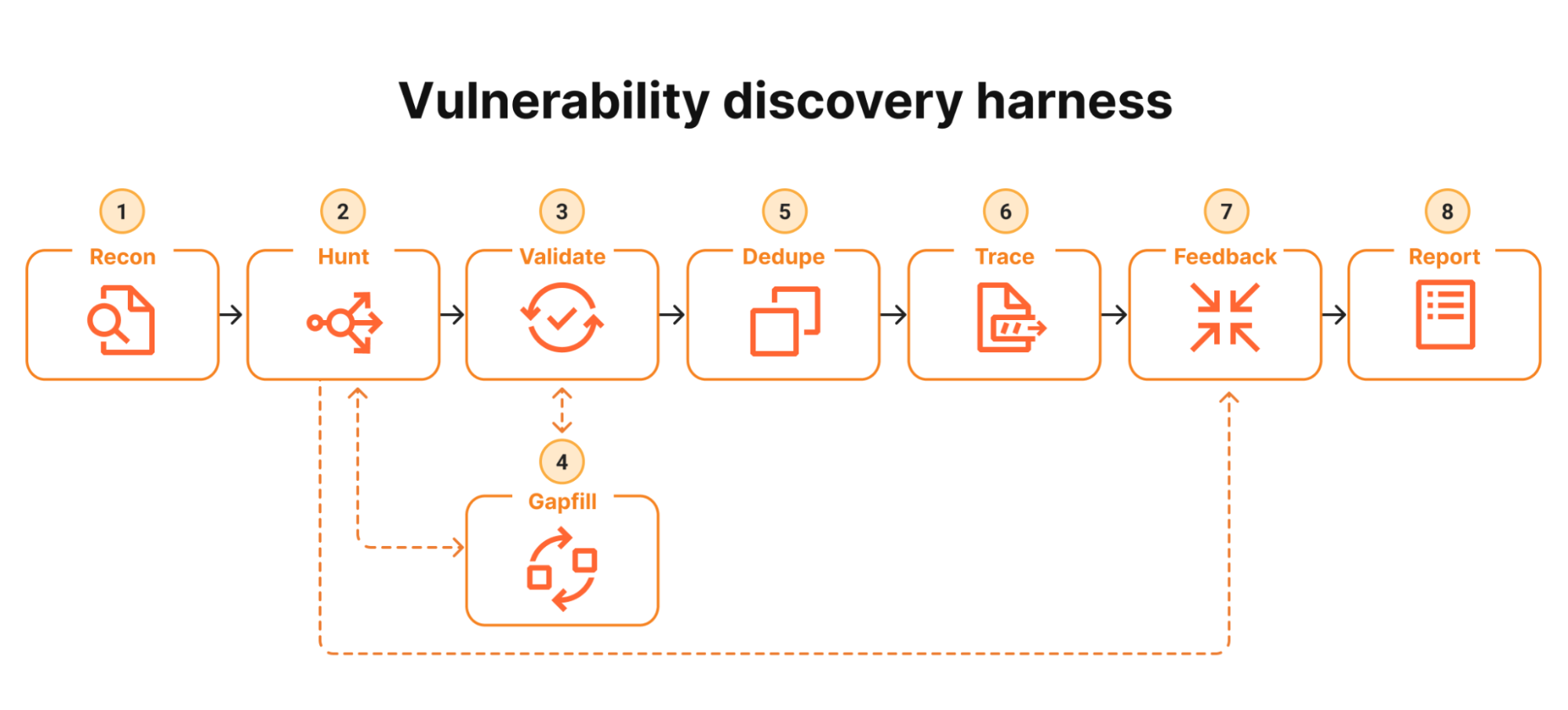
Why Human Review Still Decides Which Bugs Truly Matter
Despite their sophistication, neither CodeMender nor Mythos removes the need for human judgement. Google has explicitly designed CodeMender so that humans approve every patch, reinforcing the principle that AI security testing should augment, not replace, expert oversight. Mythos’s emergent guardrails and inconsistent refusals demonstrate the same point from another angle: even a highly capable model can behave unpredictably, alternately over-restricting or over-sharing depending on prompt context. For defenders, the lesson is clear. AI code agents can dramatically accelerate code vulnerability detection, exploit analysis, and automated security scanning, but they cannot yet own the final call on production changes or disclosure. The most resilient setups pair these agents with clear governance: strict access, logging, sandboxed execution, and human-run risk reviews. In this configuration, CodeMender and Mythos become powerful force multipliers—while accountability and strategy stay firmly in human hands.