
What MiniMax M3 Is and Why It Matters
MiniMax M3 is a frontier multimodal coding model that combines a one-million-token long context window AI architecture with native support for text, image and video inputs, targeting developers who need coding agents that can run long, tool-using workflows over large codebases and documentation. Unlike general chatbots, the MiniMax M3 model is framed as infrastructure for agents that live inside a repository, call tools and recover from partial failures during complex tasks. MiniMax positions M3 as available through MiniMax Code, token plans and API services, promising to open-source model weights and a technical report within days of launch. The release signals a shift in competition away from conversational polish toward stack integration: M3 is meant to sit alongside editors, CI pipelines and issue trackers as another programmable component that can keep state over long sessions.
Long Context Window AI for Real-World Codebases
M3’s headline feature is its one million-token context window, with a stated 512,000-token guaranteed minimum context, so long context window AI workloads can be planned around a concrete floor rather than a marketing peak. For coding agents, that scale means entire services, thick documentation sets and multi-issue histories can sit in a single prompt, reducing brittle chunking logic. MiniMax claims that its MiniMax Sparse Attention, built on a Grouped-Query Attention backbone, cuts per-token compute at million-token scale to one-twentieth of the prior generation, with more than 9 times faster prefilling and more than 15 times faster decoding compared to M2. This matters because long context is often limited by cost and latency rather than pure model quality. If those prefilling and decoding gains hold outside MiniMax’s infrastructure, M3 could make long-context agents practical for day-to-day development instead of an occasional experiment.
Multimodal Coding Model for Agents, Not Chatbots
M3 is pitched as a multimodal coding model from the ground up, not a text-only system with bolted-on vision. It supports text, image and video input with text output across OpenAI-compatible endpoints, so developers can plug it into existing API-based tools. This design fits coding agents that must read terminal screenshots, architectural diagrams or UI mockups alongside source code and documentation. MiniMax ties M3 tightly to MiniMax Code, an agent product that can break work into multi-stage workflows, use producer–verifier loops and operate computers through the model’s multimodal abilities. For teams building AI coding agents, this pairing matters more than raw language ability: M3 is presented as the core engine for autonomous development systems that track state, call tools and coordinate their own subtasks rather than as another friendly chatbot.
Benchmark Signals and Competition With Claude and GPT
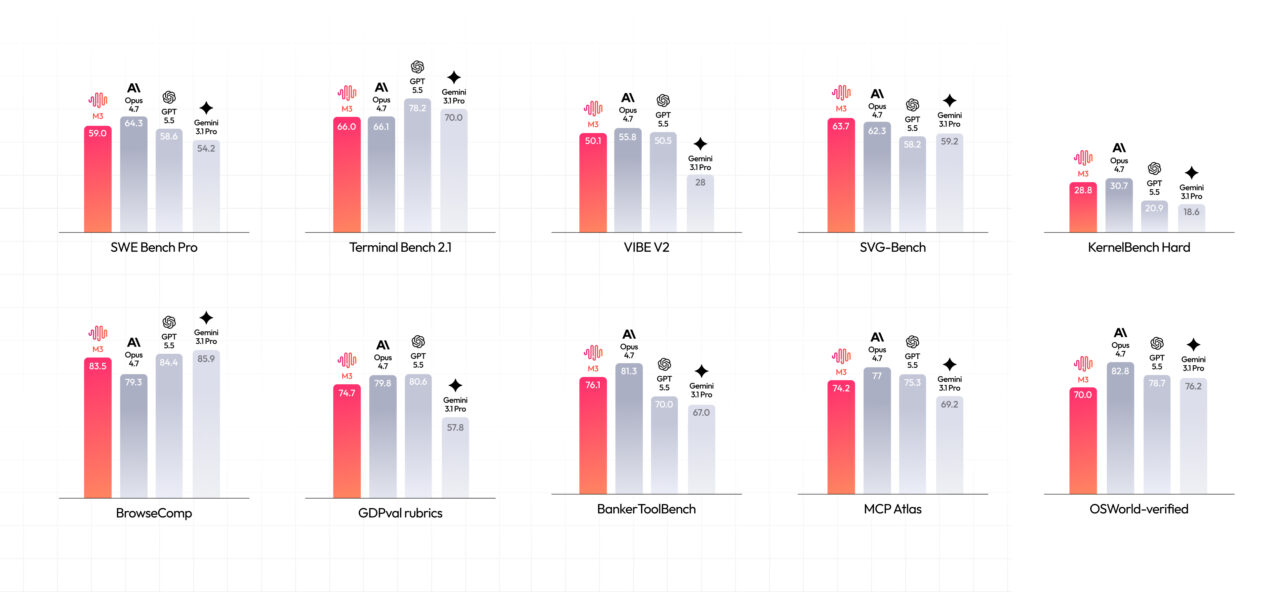
MiniMax wants M3 to sit in the same tier as Claude and GPT-4 style systems for frontier coding. It reports 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 34.8% on SWE-fficiency, 28.8% on KernelBench Hard and 74.2% on MCP Atlas. The company also states that M3 beats GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro while approaching Claude Opus 4.7, and reaches the top score on Claw-Eval, an autonomous agent benchmark. These figures should be treated carefully: MiniMax notes that many runs were done on its own infrastructure using scaffolds such as Claude Code, Mini-SWE-Agent or Terminus. At the same time, M3 does not yet appear on DeepSWE’s public board, where GPT-5.5 and Claude Opus 4.8 currently lead, so independent comparisons with the newest Claude and GPT models are still pending.
From Launch Claims to Daily Developer Use
MiniMax is rolling out M3 as an API and through the coding interface at code.minimax.io, promising to release model weights within ten days so teams can run the MiniMax M3 model more directly. Early access gives developers a way to probe latency, prompt limits and tool integrations before committing AI coding agents to production. The long context window AI story is as much about economics as raw scale: most teams will not feed an entire repository and all tickets into every prompt, but they need agents that can keep enough state without grinding workflows to a halt. If MiniMax Sparse Attention performs as described, M3 could lower the cost of long-running coding sessions compared to earlier generations, bringing competition to a space currently dominated by Claude and GPT-4 style systems and giving developers another viable engine for complex, autonomous development tasks.





