What Gemma 4 12B Is and Why It Matters for Local Multimodal AI
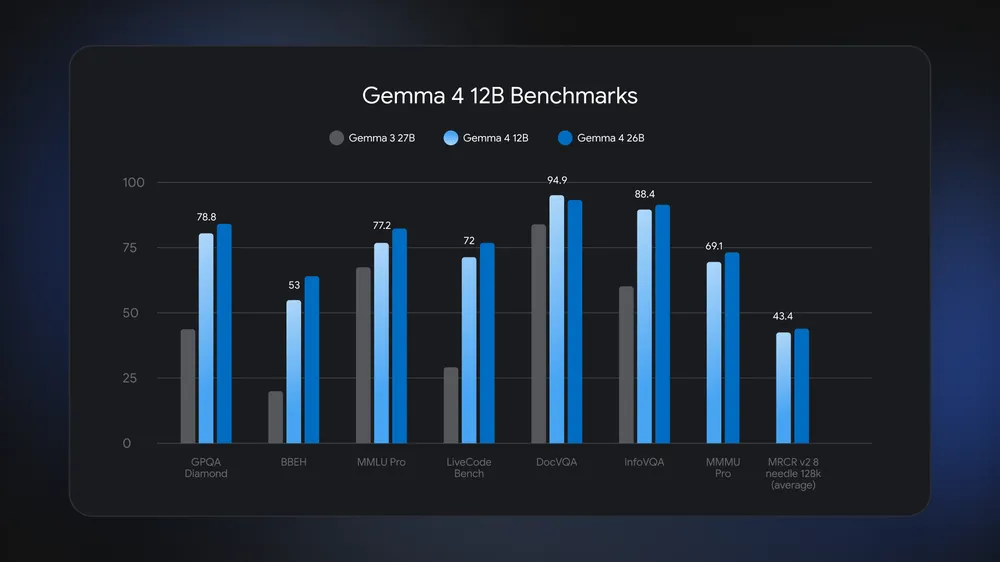
Gemma 4 12B is a 12-billion-parameter open-weight multimodal language model from Google DeepMind that processes text, images, audio, and code directly on consumer laptops with 16GB of RAM, bringing enterprise-grade local multimodal AI capabilities to devices that lack dedicated accelerators and eliminating the need for separate vision and audio encoders to enable efficient on-device AI inference. Positioned between phone-class and workstation-class Gemma 4 variants, it runs on any machine with 16GB of system RAM or VRAM while staying close to the larger 26B Mixture of Experts model on benchmarks and beating Gemma 3 27B in tests like GPQA Diamond, MMLU Pro, and DocVQA. This middle tier matters for laptop AI models because it supports multistep reasoning and agent-style tasks without cloud infrastructure, shifting the economics of local multimodal AI toward cheaper, privacy-preserving on-device deployments that developers can ship as desktop or browser applications.

Encoder-Free Architecture: How Gemma 4 12B Handles Images and Audio
The most striking technical choice in Gemma 4 12B is its encoder-free architecture for vision and audio. Where many local multimodal AI systems route non-text inputs through heavy encoders, Gemma 4 12B feeds them almost directly into the language backbone, shrinking memory and latency. For vision, a slim 35-million-parameter embedding module replaces 27 vision transformer layers and roughly 550 million parameters in the larger Gemma 4 models, splitting images into 48×48 patches and projecting each with a single matrix multiplication while keeping spatial layout through positional embeddings. Audio goes further: raw 16 kHz waveforms are sliced into 40-millisecond frames and projected into the same vector space as text, with no separate encoder. This design keeps the model light enough to run on 16GB laptops while still supporting speech recognition, speaker diarization, image understanding, and even video analysis in a single unified pipeline.
LiteRT-LM and Multi-Token Prediction: Speeding Up On-Device AI Inference
Performance is critical for laptop AI models, and Gemma 4 12B leans on Google’s LiteRT-LM runtime to push on-device AI inference speeds. LiteRT-LM adds a specialized orchestration layer on top of LiteRT, the successor to TensorFlow Lite, with optimized pipelines, advanced quantization, and accelerated XNNPACK and MLDrift kernels tuned for large language models. A key feature is native Multi-Token Prediction (MTP) support: lightweight drafter models speculatively guess multiple future tokens that the primary model then verifies in parallel. According to Google, this yields up to 2.2× faster inference for some Gemma 4 variants compared with naive decoding approaches. The runtime enforces memory locality so both the drafter and main model run on the same hardware, sharing KV cache and activations to avoid slow cross-device data transfers. Combined with session management that can save and restore cache state, LiteRT-LM makes Gemma 4 12B practical for longer, interactive local multimodal AI sessions on everyday hardware.

Open Weights, Local Agents: Shifting the Economics of Laptop AI Models
Gemma 4 12B’s open-weights release under an Apache 2.0 license removes many licensing and deployment hurdles for developers building local multimodal AI agents. The weights, about 18GB and available on platforms like Hugging Face and Kaggle, allow teams to integrate the model into desktop tools, IDE copilots, offline transcription apps, or privacy-focused chat assistants without cloud dependencies. Because it runs on standard 16GB laptops and uses an encoder-free architecture, developers can ship features such as speech recognition, code generation, and video understanding as entirely local features rather than remote services. That shift changes cost structures by reducing or removing server-side inference bills, and it cuts latency because user inputs no longer travel across networks. For users, it also strengthens privacy: images, audio, and documents stay on-device. In effect, Gemma 4 12B helps redefine on-device AI inference as a first-class option, not a compromise or afterthought.





