Refactoring Becomes the New Battleground for AI Coding Agents
Scale Labs has introduced a Refactoring Leaderboard that evaluates AI coding agents on one of the hardest engineering tasks: changing code structure without changing behavior. As part of its broader SWE Atlas research suite, the new benchmark shifts focus away from isolated coding prompts toward full software engineering workflows. Instead of just generating snippets, agents are assessed on how well they understand large repositories, modify multiple files, and keep existing tests green while performing complex code refactoring. This marks a significant evolution in how code quality metrics are applied to AI tools. Refactoring performance is quickly emerging as a core differentiator between AI coding agents, highlighting which systems can operate more like real software engineers. For enterprises wrestling with sprawling legacy systems and technical debt, the ability to reliably restructure production-style code could become as important as raw coding speed or completion accuracy.
Inside SWE Atlas: From Coding Prompts to Production-Style Refactoring
SWE Atlas is designed to treat AI coding agents as if they were members of an engineering team, not just autocomplete engines. Earlier components of the suite focus on codebase comprehension and test writing; the Refactoring Leaderboard completes the picture by testing large-scale structural changes. According to Scale Labs, these refactoring tasks require roughly twice as many lines of code changes and 1.7 times more file edits than SWE-Bench Pro, turning them into a higher-pressure test of multi-file software engineering work. Tasks span decomposing monolithic implementations, replacing weak interfaces with stronger abstractions, extracting duplicated logic into shared modules, and relocating code to sharpen module boundaries. Success is measured not only by passing tests but also through rubric-based reviews that inspect maintainability, artifact cleanup, documentation, and avoidance of anti-patterns, raising the bar for what counts as high-quality AI-generated refactoring.
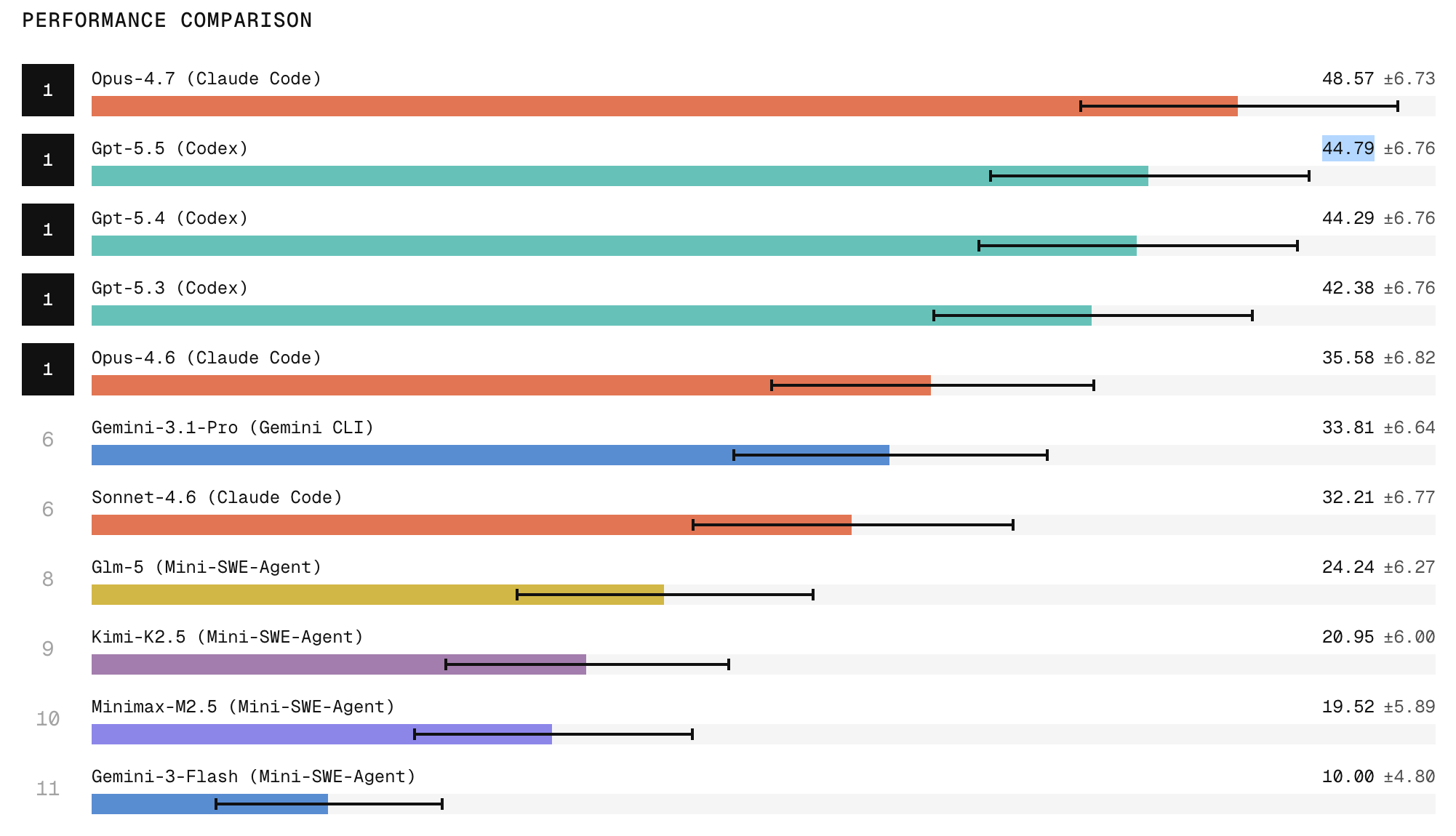
What the Refactoring Leaderboard Reveals About Model Capabilities
Early results on the Refactoring Leaderboard show clear stratification among AI coding agents. Claude Code with Opus 4.7 currently ranks first, with research indicating it produces the strongest refactors among tested systems, while ChatGPT 5.5 follows in second place. The leaderboard also exposes a wide performance gap between frontier closed models and open-weight models, particularly on tasks requiring broad repository exploration, structural edits, and behavior preservation. One notable finding is that many agents can produce refactors that pass tests yet still fail qualitative engineering checks. Dead code, stale imports, duplicated implementations, outdated comments, and missed call sites often remain. This “cleanup” gap separates tools that merely complete an obvious task from those capable of production-grade, maintainable changes. For enterprises, the ranking offers rare transparency into which AI coding agents are genuinely ready to touch critical codebases.
From Passing Tests to Sustained Code Quality and Lower Technical Debt
The benchmark’s emphasis on cleanup and maintainability turns refactoring performance into a proxy for long-term code quality. By rewarding agents that remove dead code, update documentation, and avoid anti-patterns, the Refactoring Leaderboard aligns directly with how engineering teams think about technical debt. Better code refactoring from AI coding agents could help organizations gradually reshape monolithic systems, clarify abstractions, and centralize duplicated logic, all of which reduce the cost of future changes. This transforms AI from a tool that simply accelerates feature delivery into one that can actively improve code quality metrics over time. However, the research also underscores reliability as a key bottleneck: models are two to three times more likely to succeed at least once across three attempts than to succeed in all three. That inconsistency limits their suitability for unattended, fully automated refactoring pipelines today.
Why Reliability and Transparency Now Matter More Than Raw Power
Scale Labs’ findings highlight that the conversation around AI coding agents is shifting from peak capability to dependable performance. Jason Droege, the company’s CEO, frames reliability as the central hurdle: while leading models like Opus 4.7 are improving, their consistency is not keeping pace with their raw skills. The Refactoring Leaderboard makes this visible by tracking not only whether an agent can produce a strong refactor once, but whether it can repeat that outcome under similar conditions. For enterprises, this transparency reduces the risk of blindly adopting tools whose impressive demos mask unstable behavior. It also offers a roadmap for vendors: closing the gap on repeatability, codebase understanding, and artifact cleanup is now a competitive imperative. As benchmarks like this mature, they are likely to shape procurement decisions and engineering standards around AI-assisted refactoring and broader software development workflows.