
What Claude Opus 4.8 Is and Why It Matters for Developers
Claude Opus 4.8 is Anthropic’s newest flagship large language model aimed at improving AI code quality, speeding up agentic workflows, and making autonomous AI behavior more reliable and honest for production development environments. The upgrade arrives only weeks after Opus 4.7 and targets developer tools that depend on consistent coding performance, long-running tasks, and multi-step reasoning. Anthropic positions Opus 4.8 as an evolution rather than a reset: the architecture stays in the Opus 4 family, but the model is designed to be around four times less likely to let its own code flaws slip through and to perform 2.5x faster in its fast mode than before. For engineering teams under pressure to ship more with fewer regressions, Opus 4.8 is framed as a practical, drop-in improvement rather than a risky new platform.
AI Code Quality: Fewer Flaws, Sharper Judgement
Anthropic’s headline claim for Claude Opus 4.8 is a significant jump in AI code quality. According to Anthropic, “Opus 4.8 is around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.” Internal evaluations show its agentic coding score rising from 64.3% to 69.2%, with gains in multidisciplinary reasoning with tools and agentic financial analysis as well. Early testers report that the model flags uncertainty more often and avoids unsupported claims, which matters when using AI for refactors, bug hunts, and code reviews. For day-to-day developer tools, this means fewer silent failures and more explicit signals when the model is unsure. In practice, Opus 4.8 is built to behave more like a cautious senior engineer than an overconfident junior, catching its own mistakes more often before they reach production.

Benchmarks: Opus vs GPT-5.5 and Gemini 3.1 Pro
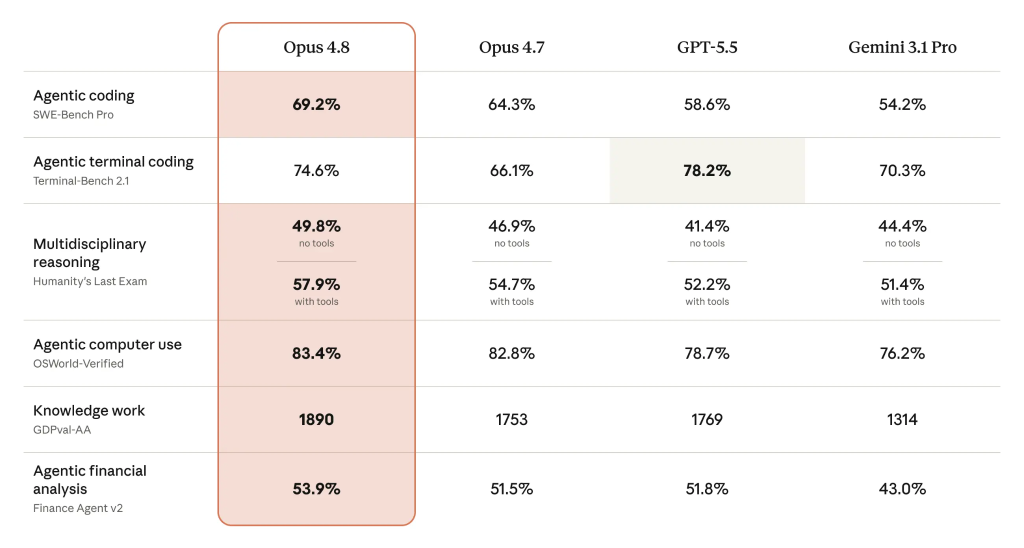
On AI benchmarks, Claude Opus 4.8 takes a clear swing at its main rivals. Anthropic reports a 69.2% score on SWE-Bench Pro, beating GPT-5.5 and Gemini 3.1 Pro on that coding benchmark. It also lifts its agentic compute use score to 83.4%, ahead of both competing models, though GPT-5.5 still leads on agentic terminal coding by about 3.6 percentage points. Knowledge work scores rise from 1753 to 1890, suggesting broader improvements beyond pure coding performance. While launch benchmarks do not always match real-world workloads, the pattern is consistent: Opus 4.8 improves on 4.7 across almost all measured dimensions and edges out GPT-5.5 and Gemini 3.1 Pro in most categories relevant to coding performance and AI agents. For teams deciding between ecosystems, these results signal that Anthropic’s stack is now competitive at the top end of AI benchmarks.
Pricing, Effort Controls, and Fast Mode for Developer Workflows
Anthropic keeps pricing steady for Claude Opus 4.8 at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, which means teams can swap from 4.7 without budget changes. At the same time, fast mode gets a major update: it now runs at 2.5x the normal speed and is three times cheaper than previous models. This combination directly impacts coding performance for CI bots, documentation generators, and AI-based developer tools that depend on latency and cost predictability. New Effort Control lets users dial how much processing the model applies to a task; lower effort returns quicker answers and slows rate-limit consumption, while the default high-effort setting aims to balance speed and quality. Together, these controls give engineering leads more direct levers over cost, throughput, and response fidelity.
Dynamic Workflows and Alignment: Toward Production-Ready AI Agents
For complex software projects, the major structural change in Claude Opus 4.8 is Dynamic Workflows, currently in research preview within Claude Code. The feature lets the model plan work and then run hundreds of parallel subagents in a single session, verifying their outputs before returning results. Anthropic highlights codebase-scale migrations across hundreds of thousands of lines as a primary use case, turning what used to be multi-week manual efforts into orchestrated AI-driven workflows. On the safety side, Anthropic reports “substantially lower” rates of deception and cooperation with misuse, alongside higher scores on prosocial traits such as supporting user autonomy and working in the user’s best interests. The combination of scalable orchestration and improved honesty makes Opus 4.8 a significant step toward reliable AI agents that can operate independently for longer stretches without undermining trust in production environments.





