
What the Next Generation of OpenSearch Serverless Changes
Amazon OpenSearch Serverless is a fully managed search and analytics service that lets developers run text and vector search at scale without managing servers, now redesigned to deliver much faster resource provisioning, scale-to-zero, and lower peak costs compared to a provisioned cluster. The newly announced generation reaches general availability with a headline claim: the redesigned architecture enables 20x faster resource provisioning than the previous serverless design. This directly targets a long-standing pain point for teams building search-heavy applications on AWS search infrastructure, where slow spin-up times could delay experiments and production changes. AWS now positions OpenSearch Serverless as a core building block for agentic AI applications, thanks to native integrations with AI-focused platforms and tools. For engineering teams, the service’s new capabilities promise shorter feedback loops, more elastic capacity, and simpler serverless search deployment paths across both traditional search and AI-driven workloads.
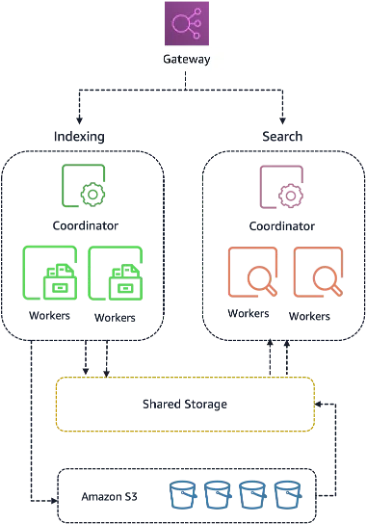
Inside the New Stateless Architecture and Shared Storage Layer
The NextGen architecture centers on a shared storage layer that decouples compute, called OpenSearch Capacity Units (OCUs), from storage, turning OCUs into stateless workers. Because data no longer lives on the OCU itself, the service can mount shared storage directly when new capacity is needed. That means OCUs do not have to bootstrap local disks, so they can start serving search and indexing traffic in seconds, which is the primary driver behind the 20x resource provisioning speedup. Stateless OCUs also enable efficient scale down: idle capacity can be released without affecting user data, improving both elasticity and cost efficiency, especially for spiky or low-duty workloads. According to AWS authors Sohaib Katariwala, Arjun Nambiar, and Raj Ramasubbu, this separation of compute and storage is the foundation of the new generation and underpins the claimed “true scale-to-zero capability” and up to 60% lower cost than a provisioned cluster at peak loads.
Endpoint and Networking Updates for Easier Multi-Collection Access
Beyond raw OpenSearch Serverless performance, AWS has reworked networking and endpoint options to simplify how applications reach collections. NextGen introduces two endpoint formats under the on.aws domain, both compatible with AWS PrivateLink so teams can create VPC endpoints for private access from internal networks or on-premise systems. The per-collection endpoint retains the familiar pattern of one collection per hostname. The new per-account regional endpoint, however, gives access to all collections in an account and region through one hostname, with the target collection specified via x-amz-aoss-collection-id or x-amz-aoss-collection-name headers. This design helps application owners manage a single connection pool, reuse TLS sessions, and streamline client configuration across many collections. For large deployments with dozens of search or vector collections, this can reduce connection churn and simplify failover and multi-tenant designs, while still keeping collection-level isolation where needed.
Collection Groups, Scale-to-Zero, and Cost Planning
Collection groups, introduced earlier and now central to NextGen, act as the control plane for how collections share capacity. Each group is defined as either Classic or NextGen, and that choice applies to every collection created within it. Developers can share compute capacity across multiple collections in a group, which is helpful for smaller workloads that would otherwise each require their own baseline OCUs. With stateless OCUs and shared storage, OpenSearch Serverless can scale search and indexing capacity to zero for idle workloads, cutting idle costs. However, as users have noted, scale-to-zero brings cold starts and initialization latency, so teams must balance lower idle spend against startup delays for end users. For many internal tools or non-latency-critical jobs, that trade-off is acceptable; for customer-facing APIs, teams may keep a small minimum OCU floor to smooth out latency while still gaining most of the efficiency benefits.
Developer Experience and Practical Implications for Search Workloads
In practical terms, the redesign shortens the path from idea to running search endpoint. Developers can create NextGen collections through the AWS console, SDK, or CLI, with support for AWS CloudFormation promised soon. The console now adds an Express create path with sensible defaults, while programmatic workflows must first define a collection group and then create collections inside it. Native integrations with AI-focused tools such as Cursor, Kiro, Claude Code, and platforms like Vercel aim to make serverless search deployment part of routine AI-agent development instead of a separate infrastructure task. Faster provisioning means teams can spin up experiments for new indexes or vector search features in minutes, test, and tear them down without long waits. For large-scale search workloads, the combination of stateless OCUs, shared capacity, and per-account endpoints should make both scaling events and multi-collection architectures easier to manage and automate.





