
From Model Sprawl to ML Infrastructure Management
Enterprises racing to operationalize AI are discovering that the real bottleneck is not model innovation, but infrastructure. As organizations accumulate hundreds of datasets, feature pipelines and models, ML infrastructure management becomes a tangle of opaque dependencies and fragile workflows. Traditional tooling treats pipelines as linear assemblies, but production reality is more like a web: datasets feed multiple models, features are reused across teams, and evaluations and services evolve asynchronously. This complexity is driving a shift toward metadata-centric platforms that treat every ML asset—and its relationships—as first-class objects. The goal is a unified model governance platform that can answer basic, yet critical questions: Where did this model come from? Which upstream data changes will break it? Who owns it and how is it used? By embedding governance and ML observability tools into the platform itself, enterprises are starting to reduce risk while still moving quickly.
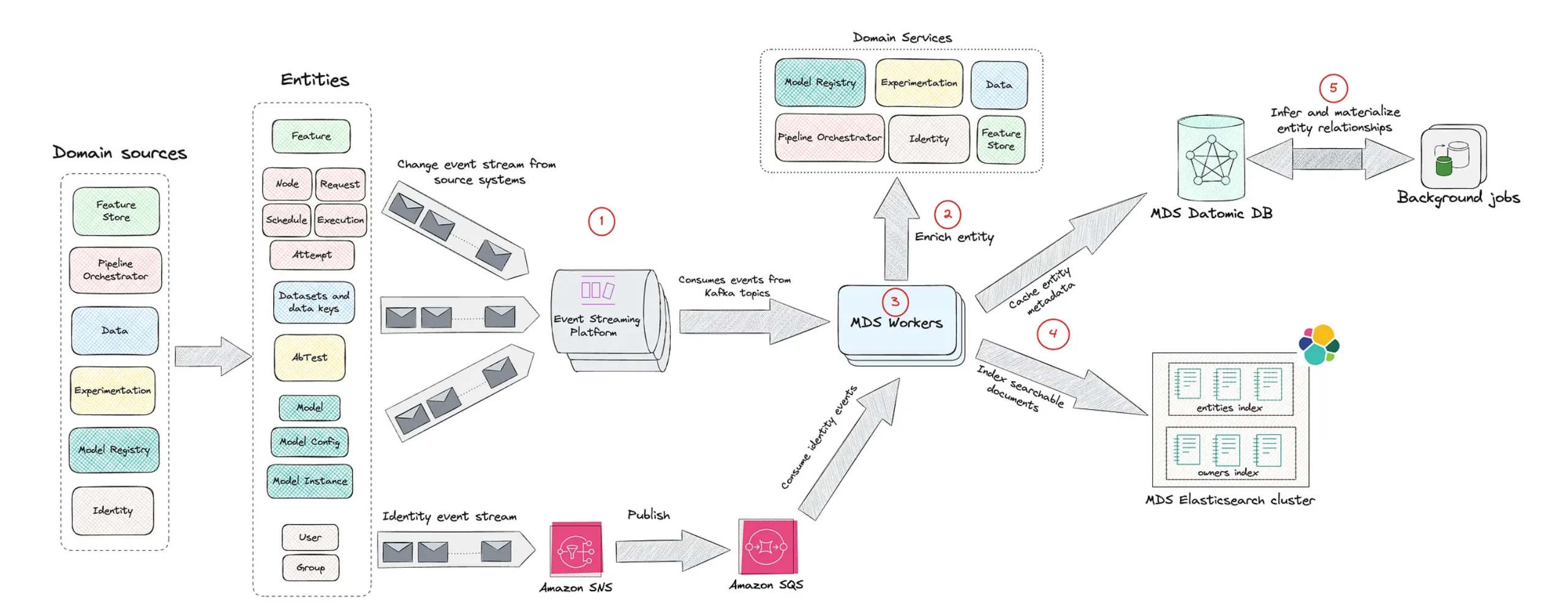
Inside Netflix’s Model Lifecycle Graph
Netflix’s Model Lifecycle Graph offers a concrete example of this new platform thinking. Instead of viewing machine learning as isolated projects, Netflix maps datasets, features, models, evaluations, workflows and production services as interconnected nodes in a graph. This structure allows engineers to traverse lineage, inspect how models are constructed and reused, and understand the downstream blast radius of any change. In practice, a single model might depend on multiple upstream datasets and derived features, each with their own lifecycle. Representing those links explicitly turns an operational headache into navigable infrastructure. The graph also improves discoverability: teams can locate existing ML assets, understand their context and avoid duplicating work. As more enterprises contend with similar levels of complexity, Netflix’s approach signals how graph-based ML infrastructure management can underpin scalable, auditable AI systems without slowing experimentation.

Integrated Platforms and the Long Road to Governance
Governed enterprise machine learning is not something most organizations can bolt on in a quarter. The Tanzu Platform story illustrates how long it can take to assemble an integrated stack with runtime isolation, multi-tenancy, automated builds, routing, service marketplaces, and zero-downtime upgrades. Earlier digital transformation waves let companies spend years composing platforms from Kubernetes-era primitives. Today, that luxury is gone. AI-driven competition is compressing timelines just as risk is rising—from unauthorized model access and shadow spend to regulatory exposure. As a result, the most forward-leaning organizations are treating governance, observability and security as the same problem as productivity. Rather than building bespoke stacks for each AI initiative, they are standardizing on shared, multi-cloud platforms that bake in policy enforcement, identity, monitoring and ML observability tools from day one.
Reframing Data Quality and Imperfect Datasets
Data quality has long been cited as the main blocker for enterprise machine learning, but that framing is starting to shift. Instead of waiting for perfectly curated datasets, enterprises are investing in infrastructure that makes imperfect data manageable. Lineage-aware platforms can trace how noisy or evolving datasets propagate into features and models, while governance layers ensure that sensitive attributes are handled correctly. ML observability tools then monitor drift, performance regression and anomalies in production, turning data issues into detectable, actionable events rather than surprises. In this model, cataloging, versioning and validating datasets becomes part of the same model governance platform that oversees model deployments and access controls. The outcome is not flawless data, but a controlled environment where trade-offs are explicit, documented and reversible—allowing AI projects to move forward without sacrificing accountability.
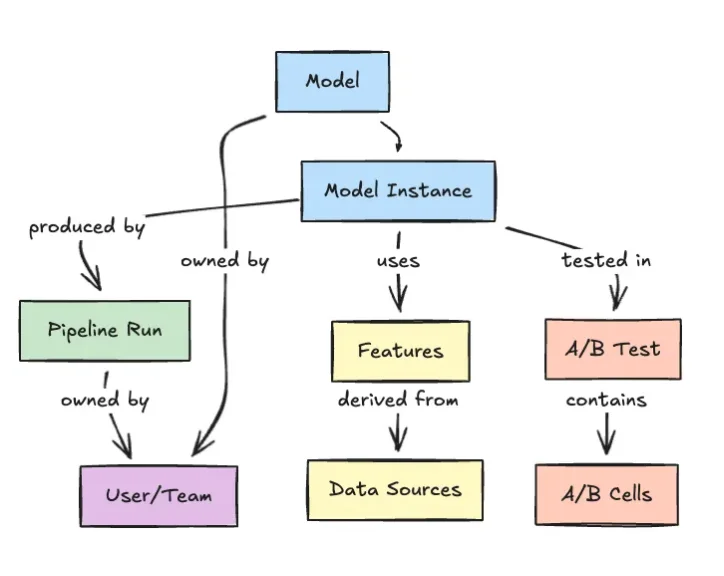
Solving the Last Mile of Enterprise Machine Learning
As models become more capable, the hardest problem in enterprise machine learning has shifted to the so-called last mile: running AI in production sustainably and at scale. Platform teams now focus on making deployment, monitoring and lifecycle management boring—repeatable, observable and cost-conscious. Graph-based approaches like Netflix’s Model Lifecycle Graph provide the visibility needed to manage change, while integrated platforms inspired by systems such as Tanzu supply the runtime, security and governance backbone. Together, they transform AI from a series of bespoke projects into a shared, enterprise-wide capability. The emerging pattern is clear: success comes from treating ML infrastructure management, model governance and observability as a single design space. Organizations that embrace this integrated view are better positioned to give employees, products and processes access to AI without losing control of risk, spend or compliance.