
What DiffusionGemma Is and Why It Is So Fast
DiffusionGemma is an experimental 26-billion-parameter text generation model from Google that uses a diffusion process instead of standard autoregressive decoding, trading some accuracy for dramatically faster on-device text generation and more responsive local AI experiences. Unlike classic large language models that predict one token at a time in sequence, DiffusionGemma denoises blocks of tokens in parallel. Built on the Gemma 4 mixture-of-experts architecture, it activates about 3.8 billion parameters per step rather than the full parameter set, which reduces memory needs and keeps inference lean enough for local GPU inference. With each diffusion step, the model refines 256 tokens at once, turning random-looking text into coherent output over several passes. This design underpins the widely discussed “DiffusionGemma speed” advantage and positions the model as a fast AI model for developers who care about latency more than leaderboard scores.
Diffusion-Based Text Generation vs Autoregressive Models
Traditional Gemma and other large language models generate text autoregressively: each new token depends on all previous tokens, which forces largely sequential computation and limits throughput. DiffusionGemma takes the opposite approach. It starts from noisy token representations and iteratively denoises them, updating many positions in parallel. In each step, up to 256 tokens attend to each other, so context is shared across the whole block rather than growing token by token. Conceptually, it resembles image diffusion models such as Stable Diffusion, but applied to sequences of text. This architectural shift allows a Gemma 4 alternative that emphasizes throughput and on-device text generation efficiency rather than maximum per-token accuracy. Because the model keeps only the active experts in memory at each step, it can run on GPUs with around 18GB of VRAM while still delivering high token rates suitable for local GPU inference workflows.

Speed Benchmarks and NVIDIA RTX/DGX Performance
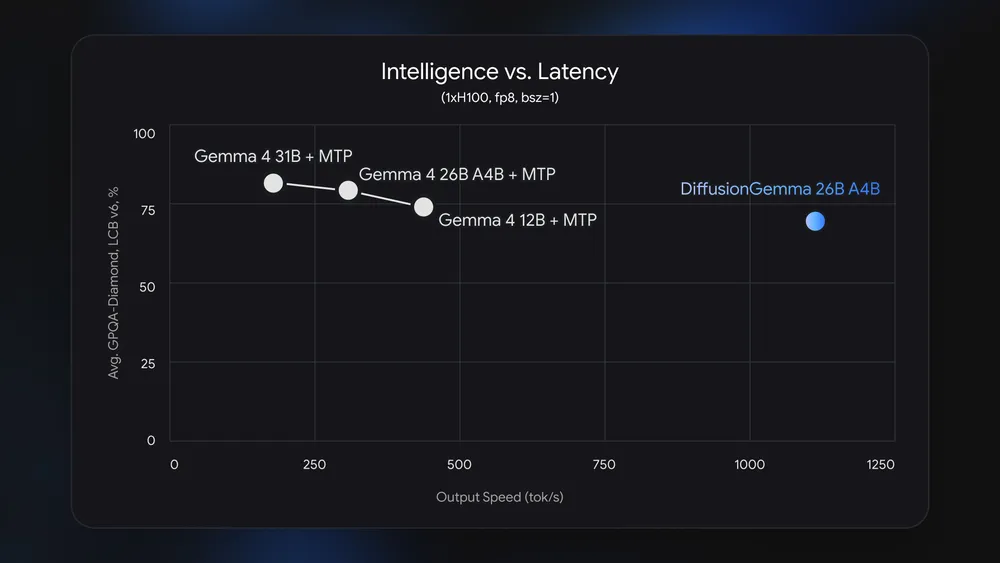
The headline feature of DiffusionGemma is speed: Google reports that it can generate more than 1,000 tokens per second on a single NVIDIA H100 GPU and up to 4x faster than equivalent autoregressive Gemma models. NVIDIA has added day-one support across its RTX and DGX platforms, further boosting practical performance. According to NVIDIA, “H100 Tensor Core GPUs on DGX Stations offer 1000 tokens/s (single GPU), DGX Spark systems offer 150 tokens/s, and DGX Station offers the fastest in-class local inference.” These figures highlight how DiffusionGemma speed makes agentic loops and rapid prototyping viable on deskside hardware. The model is available with open weights under an Apache 2.0 license and already integrates with Hugging Face Transformers, vLLM, and Unsloth, with llama.cpp support coming to GeForce RTX GPUs, making it a compelling choice among fast AI models for local GPU inference.

The Quality Tradeoff: When to Use Standard Gemma 4 Instead
DiffusionGemma’s speed comes with a cost: on standard benchmarks, it trails the Gemma 4 26B autoregressive model. Google is explicit about this tradeoff and advises using standard Gemma 4 for applications that demand maximum quality or where small accuracy gains matter more than latency. The diffusion-based approach itself is not inherently less capable, but the current model and training choices are tuned for responsiveness first. As a result, users may see slightly weaker performance on complex reasoning or long-form generation where precise, stepwise token prediction helps. The right choice depends on the job: if you are building a content assistant that drafts long articles with minimal human editing, standard Gemma 4 remains the safer option. If your product lives and dies by how fast it reacts, DiffusionGemma’s on-device text generation and low-latency behavior can outweigh its benchmark deficits.

Real-World Use Cases Where Speed Matters More Than Perfection
DiffusionGemma is optimized for scenarios where quick feedback loops are more important than perfect first drafts. Google highlights inline editing and code infilling as prime examples: the model can revise or complete spans of text while all tokens attend to each other, making local edits feel interactive instead of sluggish. The same pattern applies to interactive IDE copilots, real-time chat agents that must run locally for privacy, and tools that manipulate structured sequences such as amino acid chains or mathematical graphs. In these contexts, developers often care most about DiffusionGemma speed, smooth user experience, and predictable on-device behavior instead of squeezing out a few extra benchmark points. Because the model is an open-weight Gemma 4 alternative tuned for fast AI models and local GPU inference, it signals a broader shift from benchmark-centric design toward practical deployment speed for everyday applications.






