

Muse Spark: Meta’s Fast‑Tracked Text‑Vision‑Voice Bet
Meta Muse Spark is the company’s new multimodal AI model, designed from the ground up to handle text, vision and voice in one system. Instead of stitching a separate vision encoder onto a language model, Muse Spark integrates vision and text inside a single transformer backbone, enabling true cross‑modal attention and visual chain‑of‑thought reasoning. Meta shipped it simultaneously in the Meta AI app and on meta.ai, alongside a private‑preview API for enterprise developers, signaling how quickly it wants this multimodal AI model embedded across Facebook, Instagram, WhatsApp, Messenger and connected glasses. Early users can choose Instant mode for quick replies or Thinking mode for deeper reasoning, with a more advanced Contemplating mode—coordinating multiple sub‑agents in parallel—on the roadmap. Independent analysis places Muse Spark around fifth on a leading intelligence index, but highlights unusually high token efficiency, suggesting Meta is optimizing for speed, cost and deployability as much as for raw benchmark dominance.
Why Unified Multimodal Models Matter for Real Products
The shift toward models that natively combine text, vision and voice is reshaping how both consumers and enterprises will use AI. A single multimodal AI model simplifies product design: assistants can watch, listen and read in the same session without juggling separate tools. In Muse Spark’s case, the shared backbone and thought compression techniques aim to solve tasks with fewer internal tokens, reducing serving costs while supporting richer, cross‑modal interactions. Xiaomi’s MiMo V2.5 follows a similar philosophy, merging image, audio and video capabilities that were previously split between a text‑centric MiMo‑V2‑Pro and a weaker multimodal model. Users can, for example, upload a photo for suggestions, analyze a video tutorial or extract action points from a recorded meeting within one coherent system. For businesses, this unified text‑vision‑voice stack promises assistants that can process documents, screens and conversations together, moving beyond simple chat into complex, context‑aware workflows.
ChatGPT Images 2.0 and Xiaomi MiMo V2.5: Different Paths to Multimodality
OpenAI’s ChatGPT Images 2.0 and Xiaomi MiMo V2.5 illustrate how big tech platforms and device makers are attacking multimodality from different angles. Images 2.0 is an image‑focused upgrade: OpenAI calls it a step change in following detailed instructions, rendering dense text and arranging objects in complex scenes. It also adds reasoning features like web search and output verification, and delivers markedly better rendering of non‑Latin scripts such as Japanese, Korean, Chinese, Hindi and Bengali—critical for global users and design workflows. MiMo V2.5, by contrast, is a full‑stack multimodal family, combining text, image, audio and video in one system, with the Pro variant reaching near top‑tier benchmark results and handling complex, long‑horizon tasks. Xiaomi emphasizes efficiency, claiming MiMo‑V2.5 uses up to 42% fewer tokens than comparable systems, while pricing MiMo‑V2.5‑Pro at USD 1.00 (approx. RM4.60) per million input tokens and USD 3.00 (approx. RM13.80) per million output tokens.

Efficiency, AutoAdapt and the Push to Make Multimodal Deployable
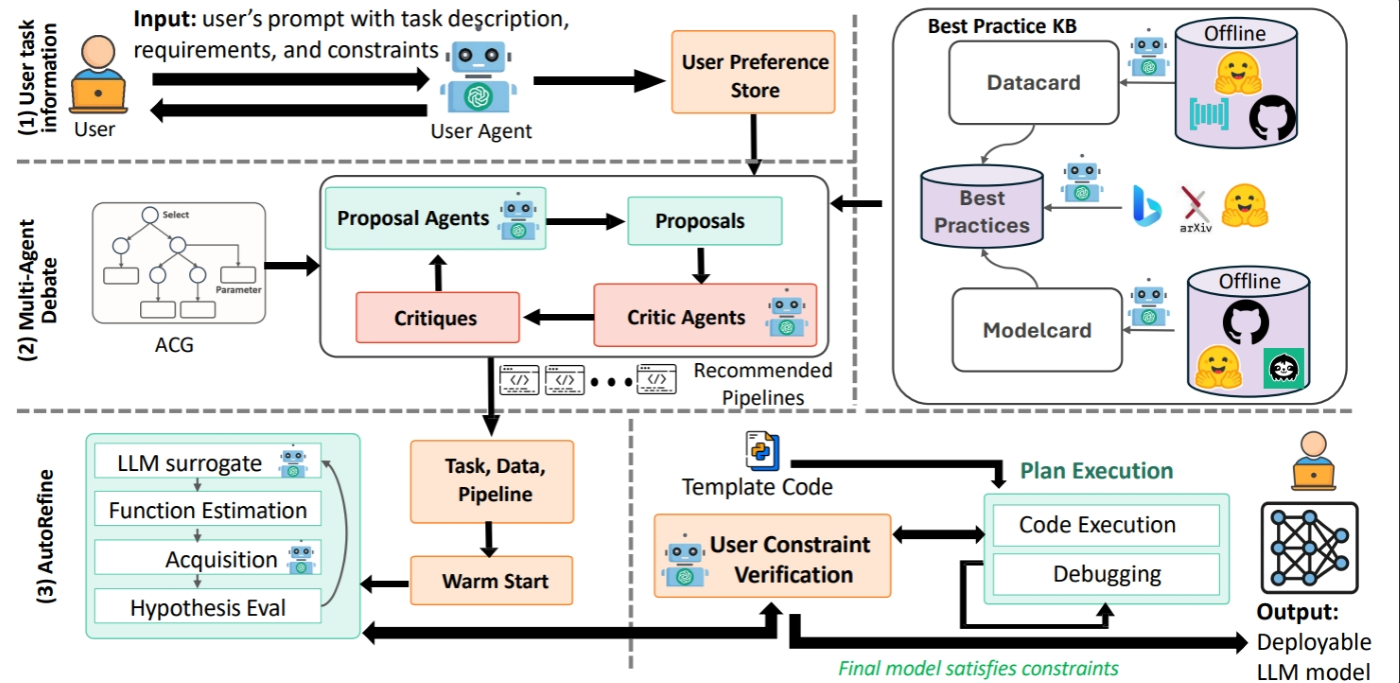
Behind the scenes, the multimodal race is increasingly about efficient adaptation and deployment, not just raw capability. Muse Spark was engineered for token and serving efficiency, using thought compression and aggressive pruning so it can spawn sub‑agents, explore solution branches and still keep costs manageable. Xiaomi’s MiMo V2.5 line similarly stresses lower token usage while delivering near top‑tier performance, making it more viable for phones, smart home devices and everyday gadgets. In parallel, frameworks like AutoAdapt show how domain adaptation for large language models is becoming more automated and constraint‑aware. AutoAdapt takes a task objective, domain data and requirements like latency, hardware and budget, then plans an executable pipeline, choosing between strategies such as retrieval‑augmented generation and fine‑tuning. Its budget‑aware optimization loop refines hyperparameters with only modest time and cost overhead, turning weeks of manual tuning into reproducible workflows—exactly what product teams need to plug multimodal systems into real‑world, high‑stakes applications.
What Users Will See First—and the Challenges Ahead
For everyday users, the first visible impact of this new generation of text‑vision‑voice systems will be richer assistants and smarter devices. Chatbots powered by models like Meta Muse Spark and Xiaomi MiMo V2.5 will not just answer text questions but also interpret screenshots, walk through video tutorials and summarize meetings. On phones and smart home gadgets, unified multimodal AI should enable on‑device assistants that can watch what you are doing, listen for context and respond naturally in voice. Cameras may offer real‑time coaching or instructions by understanding a scene rather than merely recognizing objects. Yet challenges remain: multimodal models still struggle with latency when juggling complex visual reasoning, and safety risks—from hallucinated facts to biased or harmful outputs—grow with their expressive power. Better context handling, robust domain adaptation and rigorous evaluation will be crucial to ensure these increasingly capable systems are also trustworthy and dependable.
