What RTX Spark Is and Why Local AI Matters
NVIDIA RTX Spark is a new Windows PC platform that combines Blackwell-based GPUs, multi-core CPUs, and a full AI software stack to run personal AI agents and generative models directly on the device instead of in the cloud. Designed for creators, developers, and gamers, RTX Spark systems are built as AI-first machines that can execute language models, creative tools, and automation agents with low latency and without sending every request to a remote server. NVIDIA says RTX Spark PCs can deliver up to 1 petaflop of AI power and up to 128GB of unified memory, giving laptops and desktops data-center-grade performance in a personal form factor. As Jensen Huang puts it, “For 40 years, you launched applications, clicked, wrote and PC did the rest. With RTX Spark, you ask, and the PC does the rest.”
Blackwell Architecture and the Full RTX AI Stack on Windows
At the heart of RTX Spark is NVIDIA’s Blackwell architecture, the same technology family that powers the company’s latest large-scale AI products but tuned for Windows PCs. A flagship configuration can include up to 20 CPU cores, 6,144 Blackwell GPU cores and as much as 128GB of LPDDR5X unified memory, which helps large models stay resident in memory for smoother on-device AI inference. RTX Spark also brings the wider RTX ecosystem into a single platform: CUDA for general compute, TensorRT for optimized inference, RTX graphics, DLSS, OptiX, Reflex, and G-SYNC for real-time visuals and responsive gaming. For developers, this means they can rely on the same software foundations used in NVIDIA-powered servers while targeting consumer hardware, enabling personal AI agents on Windows that feel closer to cloud-scale systems but run locally on RTX Spark PCs.
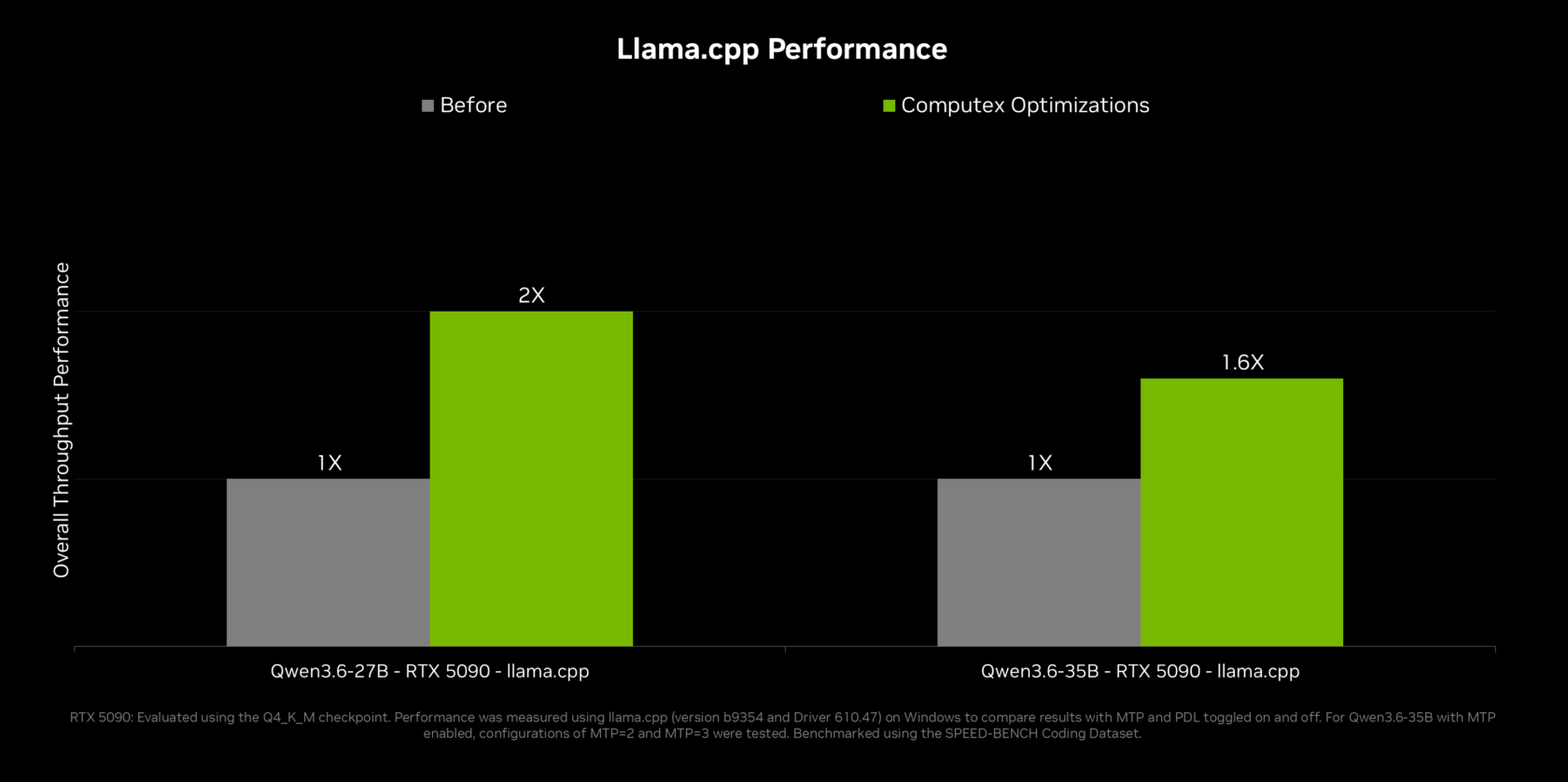
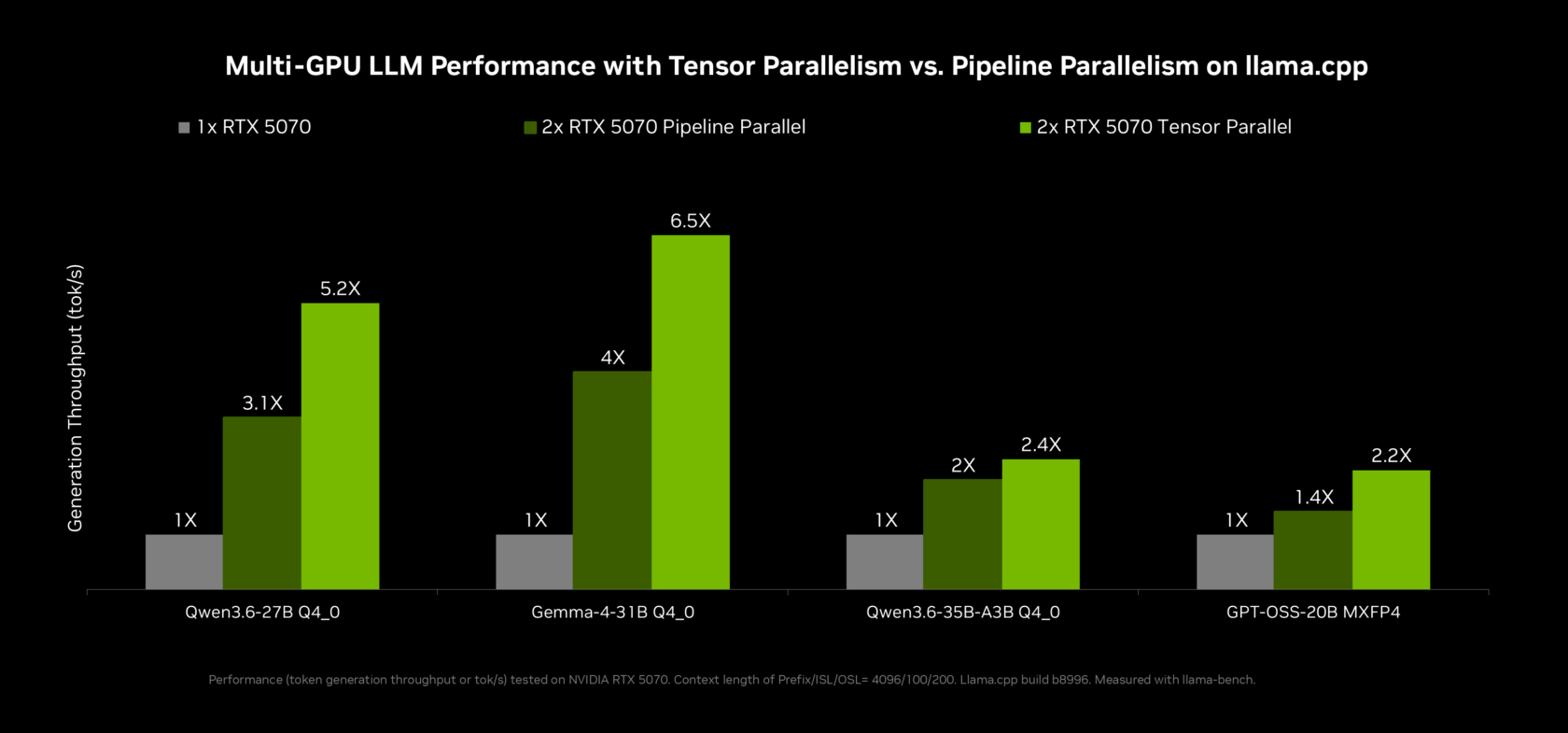
NVIDIA OpenShell and Faster On-Device AI Inference
To make RTX Spark useful for real workloads, NVIDIA is pairing the hardware with NVIDIA OpenShell, a Windows runtime for secure, on-device agent execution built on new Windows security primitives. OpenShell adds policy controls so users can define what agents are allowed to do, route queries intelligently between local and cloud models based on privacy rules, and even disguise personal information in requests that must leave the device. On the performance side, NVIDIA’s collaboration with the llama.cpp community brings multi-token prediction and other optimizations that significantly speed up local inference. According to NVIDIA, these updates can deliver up to 2x inference performance on top agentic models like Qwen 3.6 and 3.5 27B, and notable gains on larger 35B variants, helping RTX Spark PCs run complex personal AI agents Windows users can rely on for fast, interactive workflows.
What Local AI Agents Mean for Creators and Professionals
Local agentic AI on RTX Spark changes how creators and professionals can work with their tools. Instead of treating models as remote services, AI becomes a teammate that lives on the same machine as Photoshop, Premiere, IDEs, and 3D apps. Personal AI agents Windows users run on RTX Spark can automate multi-step workflows, operate other applications, generate content, or search local files without sending confidential assets to the cloud. NVIDIA highlights that agent projects like Hermes Agent and OpenClaw are integrating OpenShell and Windows security primitives so agents can act across apps while staying under user control. With up to 1 petaflop of compute and 128GB of unified memory, RTX Spark systems can host sizable local models, making on-device AI inference practical for day-to-day editing, design, code generation, and complex creative pipelines.
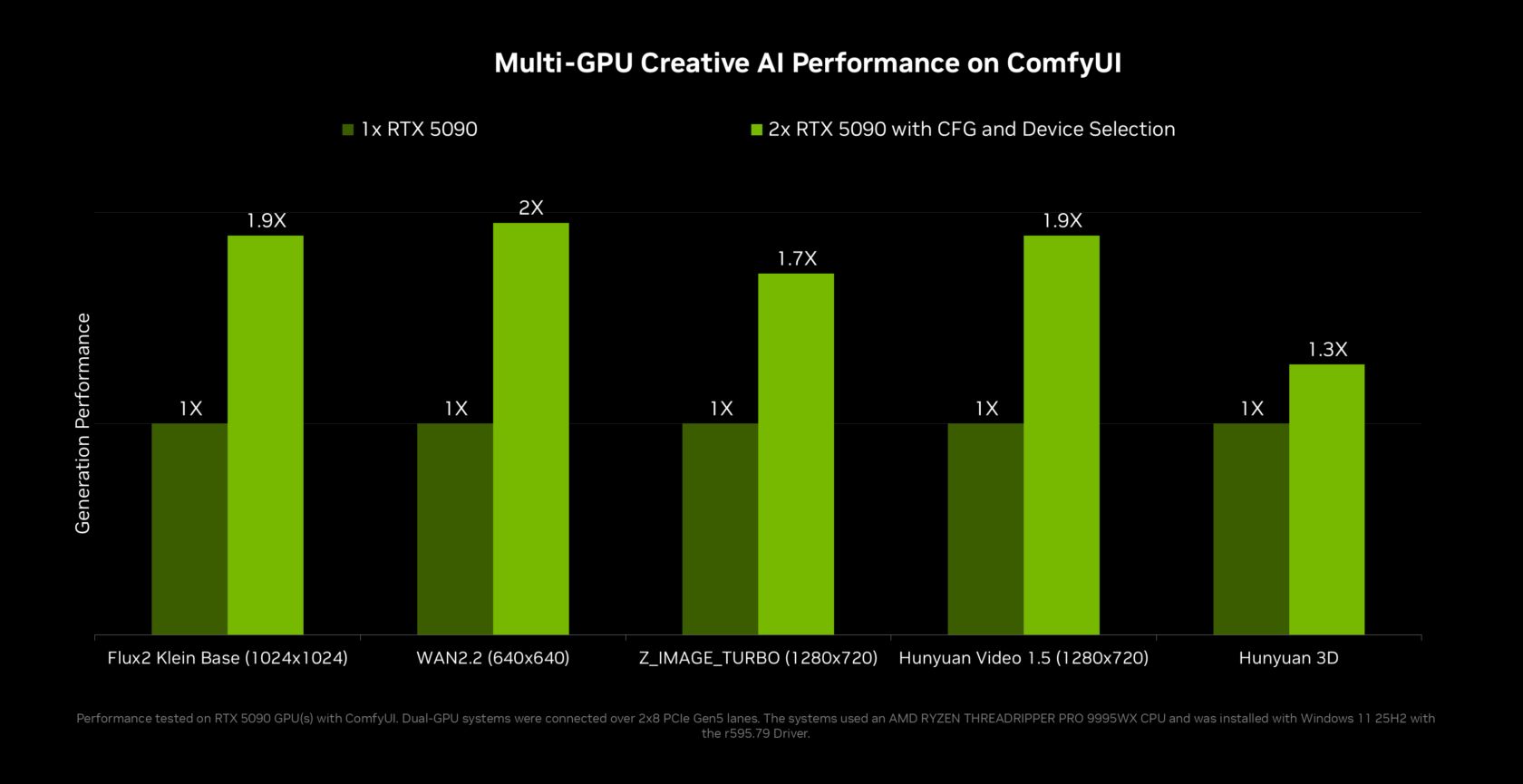
Apps Are Being Rebuilt Around RTX Spark Local AI
RTX Spark is arriving with a software ecosystem that is being refitted to exploit its AI power and memory footprint. Adobe is rearchitecting Photoshop and Premiere to take advantage of RTX Spark’s performance and unified memory, which should help larger timelines, complex effects, and AI-driven features run more smoothly on-device. Blender is adding DLSS 4.5 Ray Reconstruction, while NVIDIA is introducing RTX Video Frame Generation to tools like ComfyUI, supported by new multi-GPU optimizations for faster generation times. The NeMoClaw blueprint is expanding across GeForce RTX, RTX PRO, RTX and DGX Spark, and DGX Station, giving creators a consistent way to deploy local AI agents and models. Together with NVIDIA Broadcast 2.2 and Project G-Assist updates, these changes show a broader shift: RTX Spark local AI is turning creative apps into AI-native environments instead of thin clients for cloud services.