

From Single Calls to Agentic, Multimodal AI Pipelines
Modern multimodal AI pipelines look nothing like a simple API call to a chatbot. In an agentic AI system, a large language model acts as a reasoning unit inside a broader execution environment: it decides which tools to invoke, what information to retrieve, and how to sequence actions, but it does not directly control every downstream call. Multimodal AI adds the ability to process text, images, sensor data, and structured records in the same flow, often by composing multiple specialized models rather than relying on one monolithic multimodal model. This shift from model‑centric to system‑centric AI reflects painful production lessons. Enterprise surveys now show that fragile pipelines, opaque failures, and weak integration – not model accuracy – stall most initiatives. To move beyond demos, builders are treating AI components as unreliable dependencies that must be governed, retried, and monitored just like any other critical service.

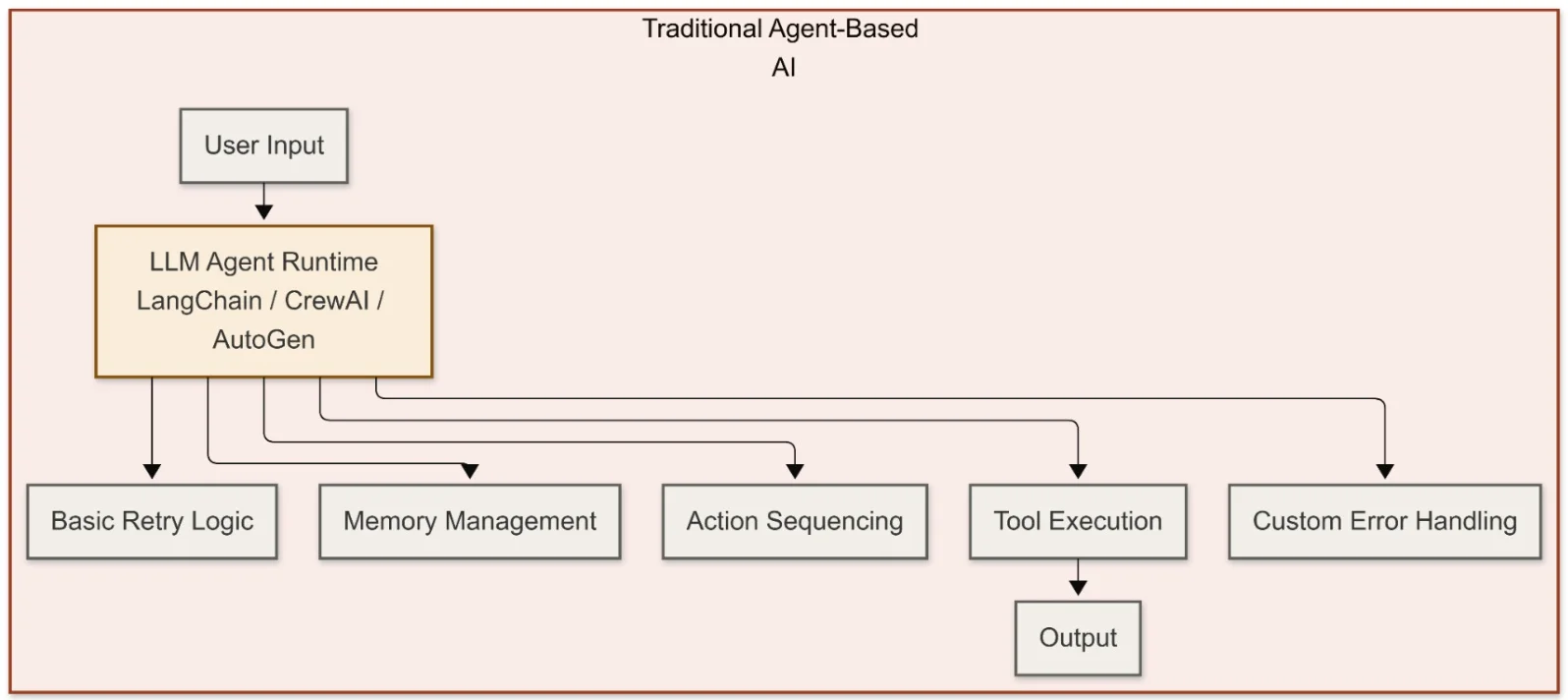
Apache Camel AI Pipelines: Reasoning Agents Inside Deterministic Flows
Using Apache Camel AI as the orchestration layer, developers can pull control logic out of the agent and into proven integration patterns. In this architecture, an LLM embedded via LangChain4j focuses on reasoning, while Camel routes govern how that reasoning is executed: they handle retries, circuit breakers, payload validation, fallbacks, and sequencing. For example, a support ticket triage pipeline can combine LLM‑based reasoning, retrieval‑augmented generation over a vector database, and image classification via TensorFlow Serving, all wired together as Camel routes rather than ad‑hoc agent code. Crucially, the LLM never queries the vector store directly; Camel owns the retrieval step, ensuring consistent behavior and observability. This approach makes multimodal AI pipelines feel like standard enterprise integrations: versionable, auditable, and resilient, even when individual models time out, return low‑confidence outputs, or need to be swapped without rewriting agent prompts.
Inside Toyota’s Vision Language Model for Smart City AI
Toyota and Woven by Toyota are applying similar orchestration thinking at city scale. Their Woven City AI Vision Engine is a foundation‑level vision language model that fuses camera feeds, mobility system data, and user inputs to detect patterns and risks in real time. Benchmarked among leading models on MVBench, it anchors an Integrated Anzen System that coordinates vehicles, infrastructure, and pedestrians as a unified, safety‑aware network. The Vision Engine is paired with Woven City Behavior AI, which interprets human movement, and Woven City Drive Sync Assist, which reads vehicle and traffic‑signal cameras. Together, these agentic AI systems allow intersections, vehicles, and sidewalks to share perception and intent. A proof‑of‑concept with UCC Japan in the Woven City Inventor Garage illustrates how developers can prototype services on top of this platform, from advanced driver assistance features to pedestrian‑centric applications and new types of mobility services.

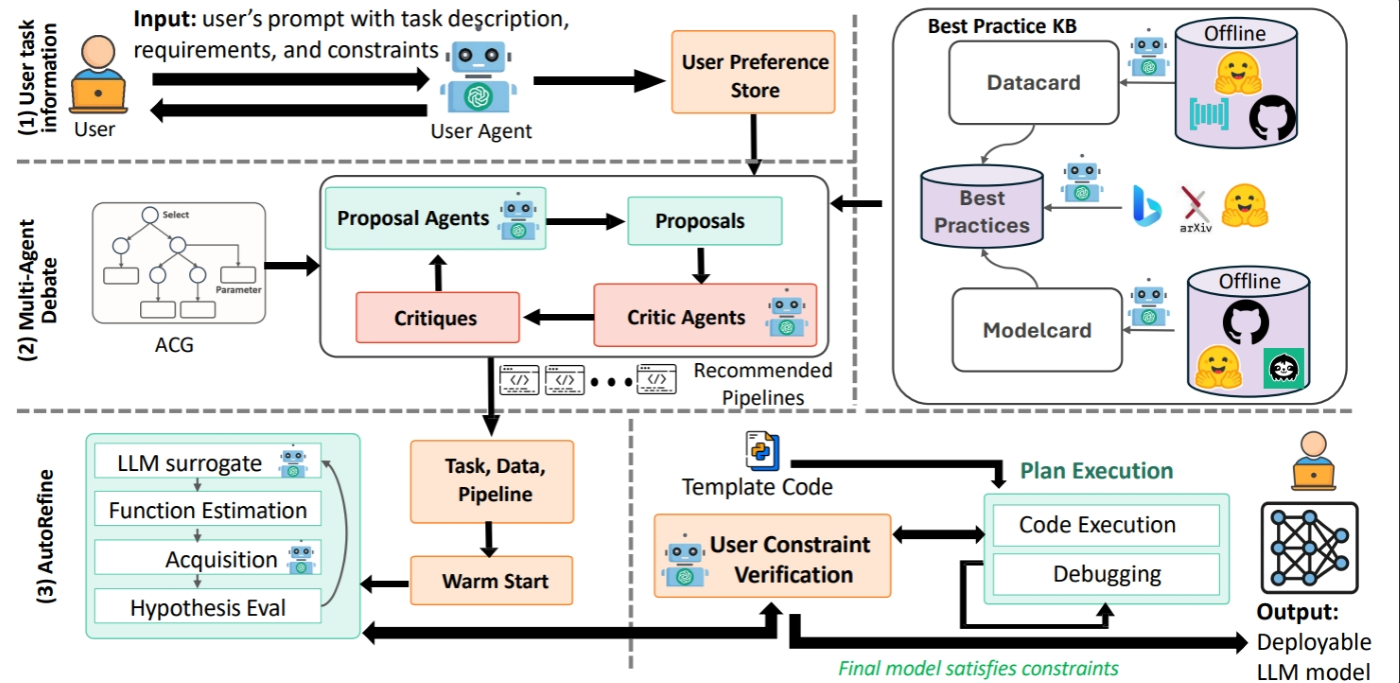
Domain Adaptation With AutoAdapt: Tailoring Models to Real Workflows
Even with strong base models and orchestrators, adapting AI to a specific domain remains a bottleneck. AutoAdapt tackles this by turning domain adaptation into an automated, constraint‑aware pipeline. Developers provide a task objective, domain data, and practical limits such as latency and privacy. AutoAdapt then builds a structured configuration graph of possible strategies, uses an agentic planner to choose between approaches like retrieval‑augmented generation and fine‑tuning, and runs a budget‑aware optimization loop called AutoRefine to iteratively improve performance. The result is a repeatable process that replaces weeks of manual trial‑and‑error with systematic planning, evaluation, and refinement. For teams wiring multimodal AI pipelines into support systems or smart city platforms, this means they can focus on orchestration and safety logic while AutoAdapt converges on a configuration that meets domain rules and operational constraints without requiring massive bespoke compute projects.
Early Urban Use Cases and the Operational Challenges Ahead
These building blocks are already pointing toward early smart city AI applications. Multimodal AI pipelines can fuse traffic cameras, mobility logs, and incident reports to optimize signal timing, detect unsafe behavior, and trigger human review. Agentic AI systems similar to Toyota’s Integrated Anzen concept could help coordinate autonomous shuttles, micromobility fleets, and pedestrian crossings, while infrastructure‑embedded agents respond to real‑time conditions rather than fixed schedules. However, shipping such systems exposes difficult engineering problems: keeping long‑horizon context manageable across text, video, and sensor streams; enforcing latency budgets when multiple models must run in sequence; securing data flows between public infrastructure and private services; and monitoring AI behavior in production with clear, auditable traces. The teams that succeed will treat multimodal agents not as magical black boxes, but as components inside disciplined, observable software systems.