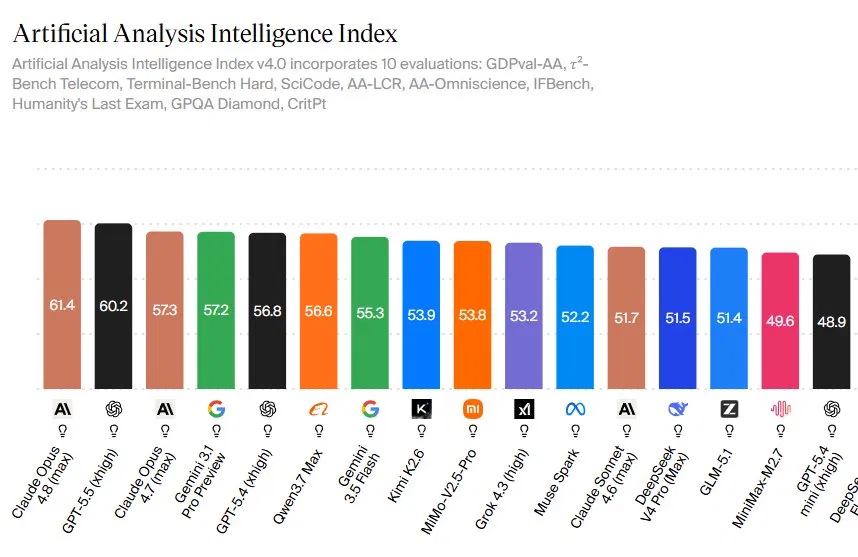
What the Artificial Analysis Intelligence Index Reveals
Claude Opus 4.8 is Anthropic’s latest flagship AI model that currently ranks as the top-performing system on the Artificial Analysis Intelligence Index, a composite benchmark designed to compare advanced models across coding, reasoning, knowledge work, and real-world agentic tasks using standardized tests. Artificial Analysis reports that Opus 4.8 scores 61.4 on its Intelligence Index v4.0, surpassing GPT-5.5’s 60.2 and Opus 4.7’s 57.3 and indicating a new leader in AI model performance comparison. The index aggregates 10 evaluations, including GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt. This breadth matters: the 1.2-point gap over GPT-5.5 stems from consistent gains across domains, not from a single outlier test. For enterprises tracking capability rankings, the Artificial Analysis Intelligence Index now places Opus 4.8 as the most capable generally available model.
GDPval-AA: Why Opus 4.8’s Real-World Lead Matters
The standout result for Claude Opus 4.8 sits on GDPval-AA, a benchmark built to mirror economically valuable, real-world AI tasks. GDPval-AA measures agentic performance on work scenarios using web and shell access across 44 occupations and 9 major industries, making it a closer proxy for enterprise deployment than many lab-style tests. Opus 4.8 achieves an Elo score of 1890 at its max setting, pulling 121 points ahead of GPT-5.5 and improving by 137 Elo over Opus 4.7. That translates to an implied win rate of about 67% in head-to-head comparisons against GPT-5.5 xhigh. For decision-makers, this suggests that in realistic workflows—research, analysis, operations—Opus 4.8 is more likely to complete tasks successfully. The model also reaches this higher score with 15% fewer turns and 35% fewer tokens than Opus 4.7, though it still uses around 30% more turns than GPT-5.5.
Benchmark-by-Benchmark: How Opus 4.8 Beats Opus 4.7 and GPT-5.5
Across specialized and general-purpose benchmarks, Claude Opus 4.8 marks a clear upgrade over Opus 4.7 and often over GPT-5.5. On agentic coding (SWE-Bench Pro), Opus 4.8 scores 69.2%, up from 64.3% for Opus 4.7 and ahead of GPT-5.5 at 58.6. Multidisciplinary reasoning via Humanity’s Last Exam tells a similar story: Opus 4.8 reaches 49.8% without tools and 57.9% with tools, leading both GPT-5.5 and Google’s Gemini 3.1 Pro. For agentic computer use, OSWorld-Verified puts Opus 4.8 at 83.4%, a narrow gain over Opus 4.7 but comfortably above GPT-5.5’s 78.7. It also leads on agentic financial analysis with Finance Agent v2 at 53.9%. One of the few areas where GPT-5.5 still holds the crown is agentic terminal coding, where it scores 78.2% on Terminal-Bench 2.1 versus Opus 4.8’s 74.6, underlining that the new Anthropic model is not dominant in every niche.

Enterprise Impact: Cost, Speed, and Agentic Use Cases
For enterprises, the Claude Opus 4.8 benchmark story is only part of the equation; price and speed also shape adoption. Anthropic has kept Opus 4.8 at the same base price as Opus 4.7—USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens—while introducing a Fast Mode that runs the same model at roughly 2.5x the speed at one-third of the previous cost. This positions Opus 4.8 squarely for longer, more autonomous workflows where an agent needs to operate over many steps with tools, browsing, or shell access. However, on GDPval-AA, Opus 4.8 still needs about 30% more turns than GPT-5.5 to complete tasks, which may matter in cost-sensitive or latency-critical settings. The trade-off is clear: slightly higher interaction overhead versus higher task completion rates and broader capability leadership.
What Opus 4.8’s Rise Signals for Future AI Rankings
Claude Opus 4.8’s position at the top of the Artificial Analysis Intelligence Index signals that capability rankings are shifting toward models optimized for agentic, real-world AI tasks rather than purely static benchmarks. Independent results now show Opus 4.8 ahead of GPT-5.5 on the composite index and on GDPval-AA, while Anthropic’s own data confirms leading scores in agentic coding, multidisciplinary reasoning, knowledge work, and financial analysis. At the same time, the gap to Anthropic’s Mythos preview model on some coding and cyber benchmarks hints that Opus 4.8 is a strong generalist rather than the absolute frontier in every domain. For enterprises, the message is that benchmark leadership is becoming multidimensional: buyers will need to weigh Artificial Analysis Intelligence Index scores, GDPval-AA performance, interaction efficiency, and pricing tiers together when choosing the best model for their workloads.






