What It Means for Open-Source AI to Match Frontier Models
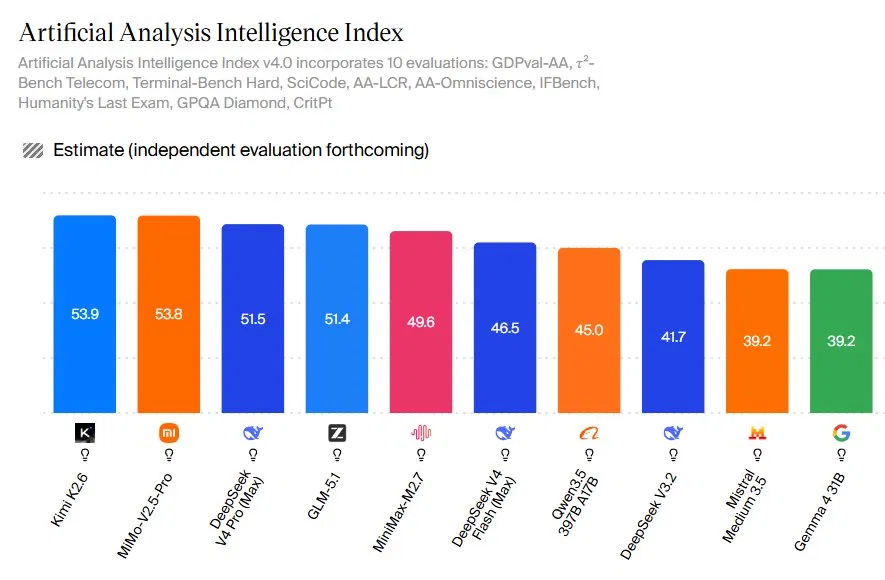
Open-source AI models are freely inspectable neural networks whose weights are released for anyone to run, modify, and integrate, and they now reach task-level performance that rivals large proprietary “frontier” systems on specific workloads while offering lower deployment costs and greater control for enterprises and developers. Instead of trying to beat every proprietary model at every benchmark, open-source AI models are becoming highly competitive for focused, real-world jobs such as coding, long-context reasoning, and agentic automation. The Artificial Analysis Intelligence Index v4.0 shows open models like Kimi K2.6, MMo-V2.5-Pro, and DeepSeek V4 Pro scoring above 50 across multi-domain tests. According to the Artificial Analysis Intelligence Index, DeepSeek V4 Pro’s 3206 Codeforces rating beats GPT-5.4 and Gemini-3.1-Pro on coding, underlining how targeted strengths can now outshine frontier models in narrow, valuable domains.
Benchmark Results: Where Open Models Now Compete Head-On
AI model benchmarks reveal that open-source AI models are no longer a tier below by default; they are competitive in chosen niches rather than across every general-purpose metric. Kimi K2.6 tops the open-source leaderboard with an Intelligence Index score of 53.9, closely followed by MMo-V2.5-Pro at 53.8 and DeepSeek V4 Pro at 51.5. GLM-5.1 scores 51.4 and posts the highest Agentic Index score among open-weights models at 63, ranking third even when proprietary models are included. These numbers matter because they reflect real capabilities: Kimi K2.6 delivered a 185% improvement in throughput when refactoring an eight-year-old financial matching engine over 13 hours with more than 1,000 tool calls. DeepSeek V4 Flash, with a score of 46.5, shows how a leaner, efficiency-focused variant can still reach strong benchmark performance while optimizing inference efficiency.
Cost-Effective AI: Efficiency Gains Without Frontier Price Tags
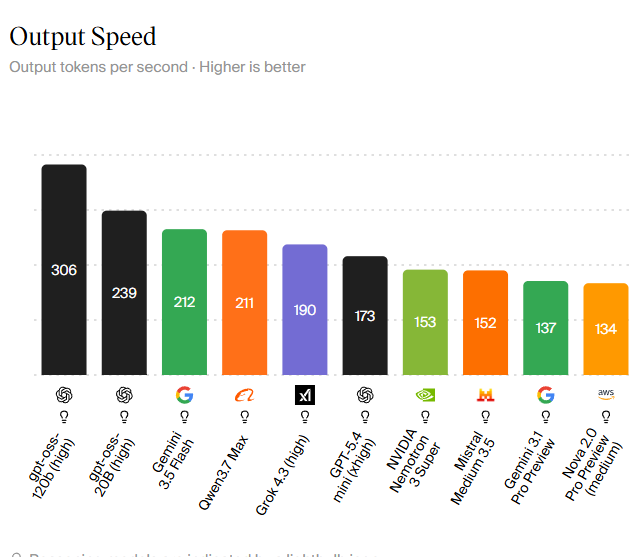
For teams seeking cost effective AI, open-source models shift the value equation by matching or approaching frontier performance while staying cheaper to run. DeepSeek V4 Flash is a clear example: it uses 284B total parameters with 13B active, and still scores 46.5 on the Intelligence Index, targeting efficiency rather than peak general capability. The provider reports that running the full benchmark suite with V4 Flash costs USD 113 (approx. RM530), compared with USD 1,071 (approx. RM4,990) for V4 Pro, while keeping 1M-token context practical at scale. On the proprietary side, speed-oriented offerings such as GPT-oss 120B and GPT-oss 20B highlight how throughput is also part of cost effectiveness. GPT-oss 120B reaches 306 tokens per second on a high-compute tier, and GPT-oss 20B hits 239 tokens per second, making speed-per-dollar a key dimension of the frontier AI comparison for production deployments.
Speed and Latency: Open vs Frontier in Real Workflows
AI model benchmarks increasingly measure speed, not only quality, because latency is what users feel in day-to-day workflows. Among proprietary systems, GPT-oss 120B at 306 tokens per second and GPT-oss 20B at 239 tokens per second lead the speed charts, with Gemini 3.5 Flash close behind at 212 tokens per second. Alibaba’s Qwen3.7 Max reaches 211 tokens per second, showing that long-context, high-throughput models are no longer limited to a single vendor. Open-weight families like Qwen 3.5 and DeepSeek’s V4 Flash are engineered for similar goals: practical long-context inference and agentic tool use that stays responsive at scale. While detailed speed metrics for every open model are still emerging, the combination of sparse architectures, token-wise compression, and mixture-of-experts routing means many open-source AI models now give a convincing alternative when latency and concurrency matter.
Choosing Between Frontier Generalists and Specialized Open Models
The frontier AI comparison now hinges on trade-offs more than absolutes. Generalist proprietary models still lead on broad, multi-modal reasoning and all-around reliability, but specialized open-source AI models can equal or exceed them in defined areas. DeepSeek V4 Pro’s top-tier coding results, GLM-5.1’s Agentic Index leadership among open-weights, and Kimi K2.6’s strong agentic and refactoring performance show how focused tuning unlocks specific advantages. Enterprises with constrained budgets or strict data-control needs gain from open models that can be deployed on-premise and adapted to their domain. Meanwhile, proprietary speed leaders like GPT-oss 120B or Gemini 3.5 Flash suit teams that value high throughput with minimal infrastructure work. The practical strategy for many organizations will be hybrid: use frontier models where general intelligence is worth the premium, and plug in cost-effective AI from open-source ecosystems for repeatable, well-scoped tasks.





