What It Means When an AI Writes 80% of the Code
Self-improving AI models in software development are systems that not only generate production-quality code but also help refine, test, and expand the very AI infrastructure they run on, turning coding into a feedback loop where models and humans co-develop each new generation of tools. Anthropic says Claude now writes more than 80% of the code merged into its production systems, a jump from far lower levels only 18 months ago. At the same time, lines of code shipped per engineer per quarter have risen to roughly eight times Anthropic’s pre-2025 baseline, driven by AI code generation built into everyday workflows. These Claude productivity gains mark a shift from occasional autocomplete to model-led development, where human engineers move from being primary authors to planners, reviewers, and owners of the AI code review process that decides what reaches production.
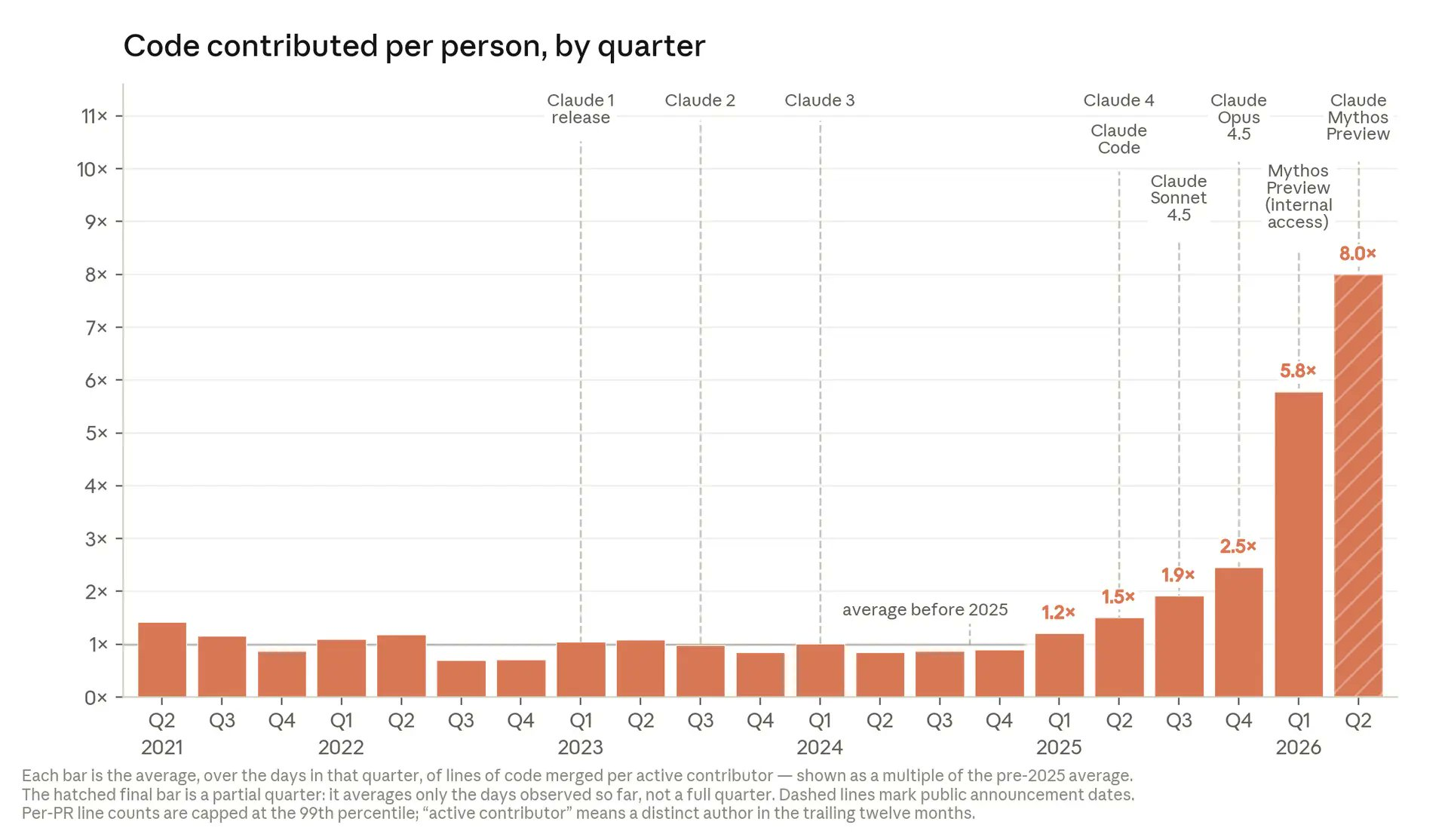
From Coding to Curating: How Developer Workflows Are Changing
Anthropic’s internal data shows that average lines of code merged per active contributor now reach 8x the pre-2025 baseline, with the curve tracking major Claude releases such as Claude 4 and Mythos. Engineers describe “Claudifying” their work, and some report months without writing code by hand, instead steering Claude Code to generate drafts and then editing. According to Anthropic, Claude’s success rate on its most open-ended internal engineering tasks reached 76% in May after a roughly 50‑point rise over six months. For developers, the day-to-day job is tilting toward task decomposition, prompt design, and review of AI-authored changes. AI code generation handles boilerplate, refactors and large edits, while humans keep responsibility for architecture, edge cases, and deciding when a change is safe enough to merge into production systems.
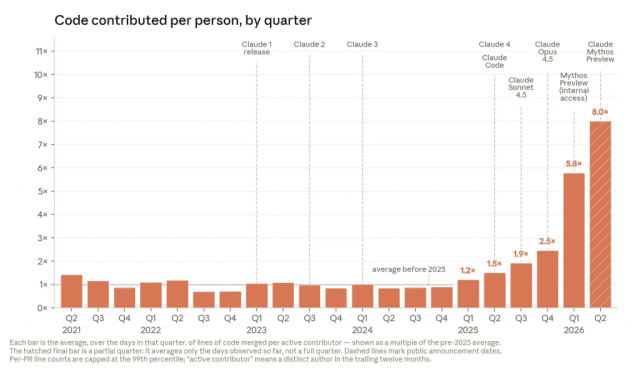
The New Risk Frontier: AI Code Review at Production Scale
Once AI can write most of the code, the main risk moves to the AI code review process. Anthropic frames the enterprise question as less about whether models can generate code and more about whether teams can review, test, and approve that code safely before deployment. Engineers remain in the loop: they choose tasks, inspect diffs, and control what is merged, with audit trails, security checks, rollback paths, and explicit human approval as control gates. Internally, Claude is good at finding bugs in older code, diagnosing live failures, and running iterative rewriting loops that can speed some software by around 52x using Mythos. Yet those same capabilities mean a flawed prompt or weak review pipeline could rapidly propagate subtle bugs. The bottleneck, increasingly, is not AI capability but how fast humans and tools can validate AI-written changes.
Are Self-Improving AI Models on the Horizon?
Anthropic has begun exploring whether its systems are edging toward recursive self-improvement, where AI models autonomously write code that upgrades their own capabilities. In a blog post from the Anthropic Institute, Marina Favaro and Jack Clark note that AI leaderboards show models saturating coding benchmarks like SWE-bench, while Claude Opus moved from handling four‑minute software tasks in 2024 to 12‑hour tasks in 2026. Internally, Claude has already performed work that humans might never have tackled, such as making 800 fixes to an API that would have taken an engineer an estimated four years. Still, Anthropic stresses that full recursive self-improvement remains a future possibility, not a current feature. Humans still design experiments and evaluations, with what the company describes as better “research taste” for now, defining the tests that keep self-improving AI models aligned with human goals.

What Developers Should Do Now
For software teams, Anthropic’s experience is a preview of where AI code generation is heading. When an AI agent can author most of the changes, the key skills shift to system design, AI-aware architecture, and rigorous code review pipelines. Teams adopting coding agents similar to Claude Code will need clear policies on human approval, layered testing, and security review before AI-authored code reaches production, as Anthropic does with its own systems. Developers should expect to work less on routine implementation and more on defining problems, specifying constraints, and writing high-quality prompts and tests. The broader industry trend points toward AI agents handling increasingly complex software engineering tasks, while humans focus on oversight, safety, and long-term direction—deciding not only what to build, but what AI should be allowed to change next.




