What Makes Ryzen AI Max PRO 400 Different?
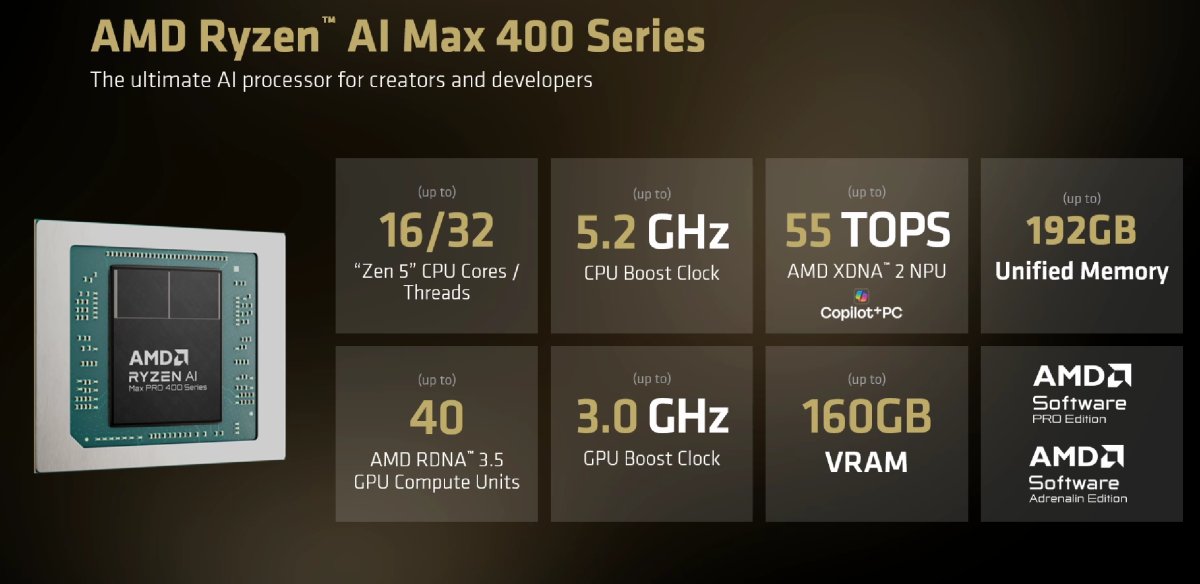
AMD’s Ryzen AI Max PRO 400 series is a mid-generation refresh of its Strix Halo (Gorgon Halo) silicon, but the changes are strategically important for AI workloads. These AI workstation chips still combine up to 16 Zen 5 CPU cores, an RDNA 3.5 integrated GPU, and an NPU capable of up to 55 TOPS in the flagship Ryzen AI Max+ PRO 495. Clock speeds get modest bumps: the CPU boosts up to 5.2 GHz and the Radeon 8065S iGPU up to 3 GHz, while the NPU gains extra headroom for on-device inference. On paper, this looks incremental. In practice, the real story is system-level: a wide 256-bit memory bus, enterprise-focused PRO features, and a power envelope from 45 W to 120 W make these chips suitable for compact workstations and developer-focused mini PCs that must run demanding AI workloads locally and consistently.

Why 192GB Memory Support Changes Local AI Models
The standout feature of Ryzen AI Max PRO 400 is 192GB memory support using LPDDR5X-8533. Compared with the previous 128GB ceiling on Ryzen AI Max 300, this is a 50% capacity jump plus about a 7% memory bandwidth increase to roughly 273 GB/s. For local AI models, capacity matters more than small clock bumps. AMD allows up to 160GB of this pool to be allocated as GPU-accessible memory, effectively functioning as massive shared VRAM. That is enough to host approximately 300B-parameter FP4 large language models on a single SoC—something previously limited to highly specialized systems. For professionals, this means fewer compromises on model size, less aggressive quantization, and the ability to keep more context or multiple models resident in memory, enabling smoother experimentation with cutting-edge LLMs directly on a laptop or mini workstation.
On-Device AI Inference at Scale for Professionals
Ryzen AI Max PRO 400 targets professionals and enterprises that need robust on-device AI inference rather than relying on the cloud. With up to 16 cores and 32 threads, the CPU handles traditional workloads like data preprocessing, code, and analytics, while the RDNA 3.5 GPU and NPU accelerate transformers, vision models, and multimodal pipelines. The ability to dedicate up to 160GB to GPU workspaces means data scientists can run large LLMs, diffusion models, or retrieval-augmented generation stacks locally, even in compact systems like AMD’s own Ryzen AI Halo developer mini PC. Combined with PRO-class manageability and security features, these chips fit well in controlled environments where data cannot leave the device. Teams can prototype, fine-tune, and deploy internal models without setting up dedicated GPU servers, shortening development cycles and reducing infrastructure complexity.
Reducing Cloud Dependence and Practical Trade-Offs
Higher memory capacity directly reduces reliance on cloud-based AI services. Instead of streaming tokens from remote GPUs, professionals can host very large local AI models, keeping sensitive data on-site and maintaining performance even with limited connectivity. Workstations powered by Ryzen AI Max PRO 400 can support multi-tenant workloads—such as separate models for code generation, summarization, and vision—within a single machine. However, the memory uplift does not magically remove all bottlenecks. Compute throughput and memory bandwidth see only marginal gains, so tasks dominated by pre-fill and token generation speeds will not accelerate dramatically. The real benefit is capability and flexibility: you can run bigger or more numerous models at once. For many organizations, that trade-off is ideal—accept similar token speeds in exchange for more powerful, private, and controllable AI workflows on their own hardware.