
From Fragmented Pipelines to a Connected Machine Learning Lifecycle
As machine learning becomes embedded in more products and workflows, traditional tooling starts to fracture under the weight of complexity. Enterprises accumulate countless datasets, feature sets, experiments and deployed models, often owned by different teams and evolving at different speeds. Netflix’s engineers argue that beyond a certain scale, simply knowing where a model came from, which upstream datasets it depends on, or which services it powers becomes a major operational challenge. Their response is the Model Lifecycle Graph, a metadata-centric view of the entire machine learning lifecycle that treats models, datasets, features and workflows as first-class entities. Instead of seeing ML as a set of isolated pipelines, the graph exposes how everything is interconnected. This shift is central to emerging practices around ML model governance and is increasingly critical for enterprise ML systems that need both rapid iteration and strong oversight.
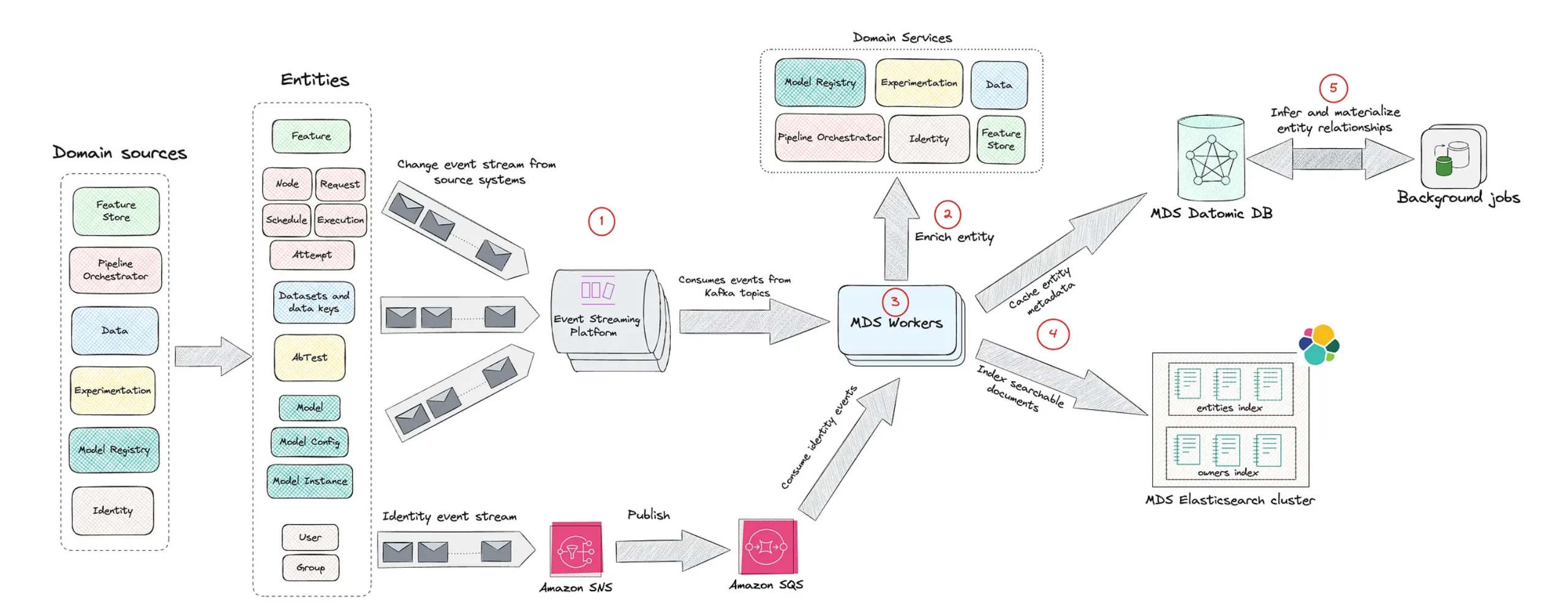
Inside Netflix’s Model Lifecycle Graph Architecture
The Model Lifecycle Graph represents machine learning assets as nodes and their relationships as edges. Datasets, feature sets, models, evaluations, workflows and production services are all modeled in a single, traversable structure. This means an engineer can start from a production service, walk upstream to the models it uses, then continue to the datasets, transformations and evaluation workflows that shaped those models. Conversely, they can start from a dataset and explore every model and system that depends on it. By aligning the machine learning lifecycle with a graph representation, Netflix can surface operational context that a pipeline-centric view often hides. The graph improves discoverability, making reusable components easier to find, and anchors governance in concrete relationships rather than ad hoc documentation. It effectively turns model lineage tracking into an everyday capability instead of a separate, after-the-fact process.
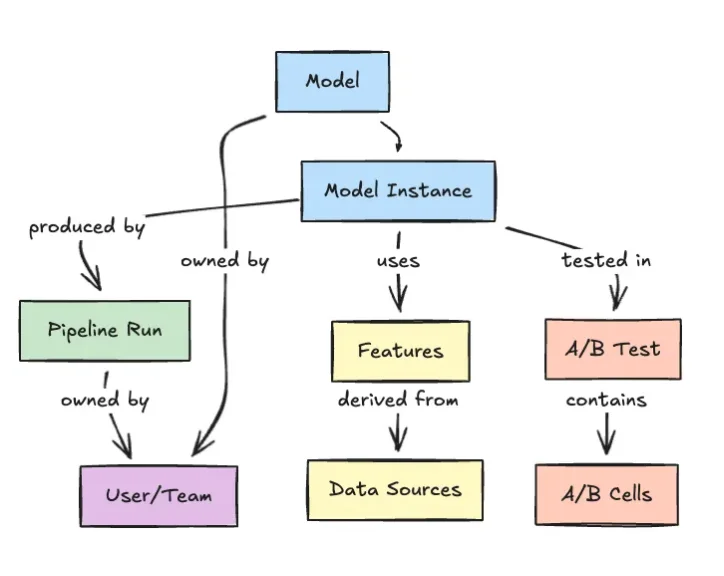
Why a Graph Suits Enterprise ML Systems
Netflix contends that graph structures are a natural fit for enterprise ML systems because no model exists in isolation. A single model might draw from multiple datasets, each with its own derived features, be evaluated through several workflows and serve various downstream products. All of these elements evolve independently, creating a dense web of dependencies. A graph-based view allows engineers to traverse this web quickly and intuitively. They can perform impact analysis before changing a dataset, assess how a workflow alteration ripples through dependent models, or pinpoint which services might be at risk from a failing component. Compared with rigid, pipeline-oriented tooling, the graph emphasizes relationships and context. This supports safer deployments, more effective model lineage tracking and a clearer picture of how machine learning decisions are embedded across complex software stacks.
Governance, Observability and Democratization of ML
Beyond technical elegance, Netflix positions the Model Lifecycle Graph as a governance and observability tool. By centralizing metadata about ownership, dependencies and usage, the graph helps clarify who is responsible for a model and how it is being used. This makes it easier to enforce ML model governance policies, ensure compliance and avoid accidental reuse of outdated or unapproved assets. The architecture also underpins a more self-service culture: rather than relying on a small platform team to answer questions, engineers and data scientists can independently explore the graph to discover datasets, understand dependencies and reuse features or models. This reduces duplication of effort while improving institutional visibility. In effect, the graph turns enterprise ML systems into a navigable knowledge map, aligning safe scaling of AI with everyday development practices.
Part of a Wider Shift to Metadata-Centric ML Platforms
Netflix’s Model Lifecycle Graph reflects a broader movement toward metadata-centric machine learning and data platforms. Similar ideas appear in tools like LinkedIn’s DataHub, which models datasets, pipelines and ownership as a graph, and initiatives such as OpenLineage that foreground lineage and observability. Uber’s Michelangelo platform likewise emphasized centralized lifecycle management and feature reuse, showing that large-scale ML demands structured metadata rather than scattered scripts and dashboards. Even internal developer portals, including those inspired by Spotify’s Backstage, are adopting graph-based representations of services, infrastructure and operational metadata. What makes Netflix’s approach notable is its emphasis on traceability and institutional visibility at a time when much of the AI ecosystem focuses on rapid experimentation and lightweight orchestration. As enterprises embed models deeper into their products, treating metadata, lineage and lifecycle governance as core architecture—rather than optional extras—appears increasingly necessary.