
Why AI Model Speed Now Matters as Much as Quality
AI model speed describes how quickly a system can process or generate tokens, and it has shifted from a niche benchmark metric into a primary factor that shapes user experience, hardware strategy, and overall AI economics across training and inference workloads. In practice, AI model speed benchmarks and tokens per second performance now decide whether chatbots feel conversational, copilots keep up with coding, and agents can act in real time instead of pausing between steps. Data from the Artificial Analysis index shows that the gap between the fastest and slowest models is large enough to determine which tools feel usable in daily work. As organizations tighten AI budgets, decision-makers are starting to compare speed-per-dollar alongside accuracy, pushing labs and cloud providers into a new race focused on throughput and latency.
MiMo-V2.5-Pro and the New Bar for GPU Inference Speed
On the inference side, Xiaomi’s MiMo-V2.5-Pro UltraSpeed Mode is redefining what high-end throughput looks like on general-purpose GPUs. Co-designed with TileRT, the 1‑trillion‑parameter model surpasses 1,000 tokens per second on standard GPUs while keeping full-scale LLM capabilities. Xiaomi notes that an earlier family member, MiMo-V2-Flash, already reached about 150 tokens per second, equivalent to roughly 110 words per second, which is faster than most people can read or speak. The new UltraSpeed mode is roughly ten times faster than standard MiMo‑V2.5‑Pro API access, but it comes at a premium: the UltraSpeed API is priced at three times the regular rate and offered through a limited, application-based trial. For enterprises that need extreme GPU inference speed, that trade-off highlights how throughput is turning into a service tier, not just a technical bragging right.
Blackwell, JAX, and MaxText: Shaving Step Time in LLM Training
If inference is about tokens per second performance, training is about how much compute you can push through each step. NVIDIA’s work on the Blackwell architecture and NVFP4 precision format targets exactly that. According to NVIDIA, “native hardware support of NVFP4 on the NVIDIA GB300 Grace Blackwell Ultra Superchip delivers 7x GEMM throughput compared to native FP8 precision on the NVIDIA Hopper.” The NVFP4 recipe, implemented in TransformerEngine and exposed through the MaxText LLM training framework for JAX, enables 4‑bit mixed‑precision pretraining with no measurable accuracy loss relative to FP8 in their reported experiments. Techniques such as micro block scaling, 2D weight scaling, selective Random Hadamard Transforms, and stochastic rounding together cut step time while keeping convergence stable. For AI factories pretraining models over trillions of tokens, even single‑digit percentage gains in step time translate into days saved and lower compute bills.
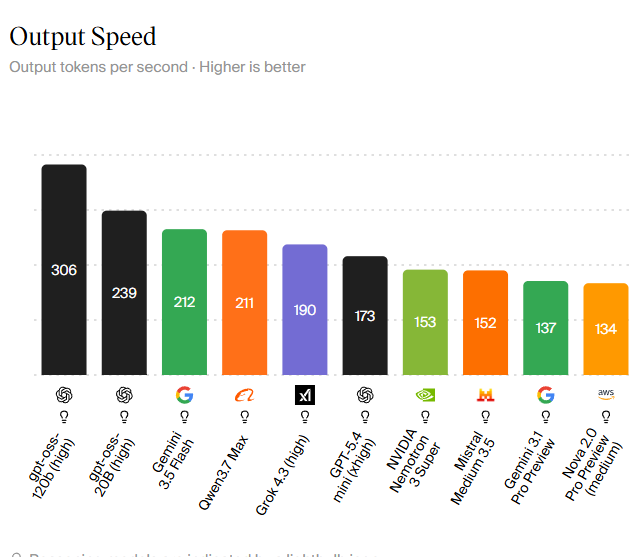
From Benchmarks to Business Impact: Speed as a Competitive Moat
Public rankings of the fastest AI models underline how speed is becoming a competitive moat. Artificial Analysis data cited by OfficeChai shows that frontier systems span from around 190 to over 300 tokens per second, with OpenAI’s GPT‑oss variants, Google Gemini 3.5 Flash, Alibaba’s Qwen3.7 Max, and xAI’s Grok all clustered near the top. In this band, GPU inference speed differences of tens of tokens per second already shape which APIs feel instant in production dashboards, customer support tools, and code assistants. At larger scale, LLM training optimization on platforms like Blackwell means AI builders can launch more capable generations sooner or iterate more frequently within the same budget. As MiMo‑V2.5‑Pro UltraSpeed illustrates at the high end, vendors are beginning to package raw speed as differentiated product tiers, turning latency and throughput into direct business levers rather than background infrastructure details.





